Transformer
Transformer
1. 从整体宏观来理解Transformer
首先,我们将整个模型视为黑盒。在机器翻译任务中,接收一种语言的句子作为输入,然后将其翻译成其他语言输出。

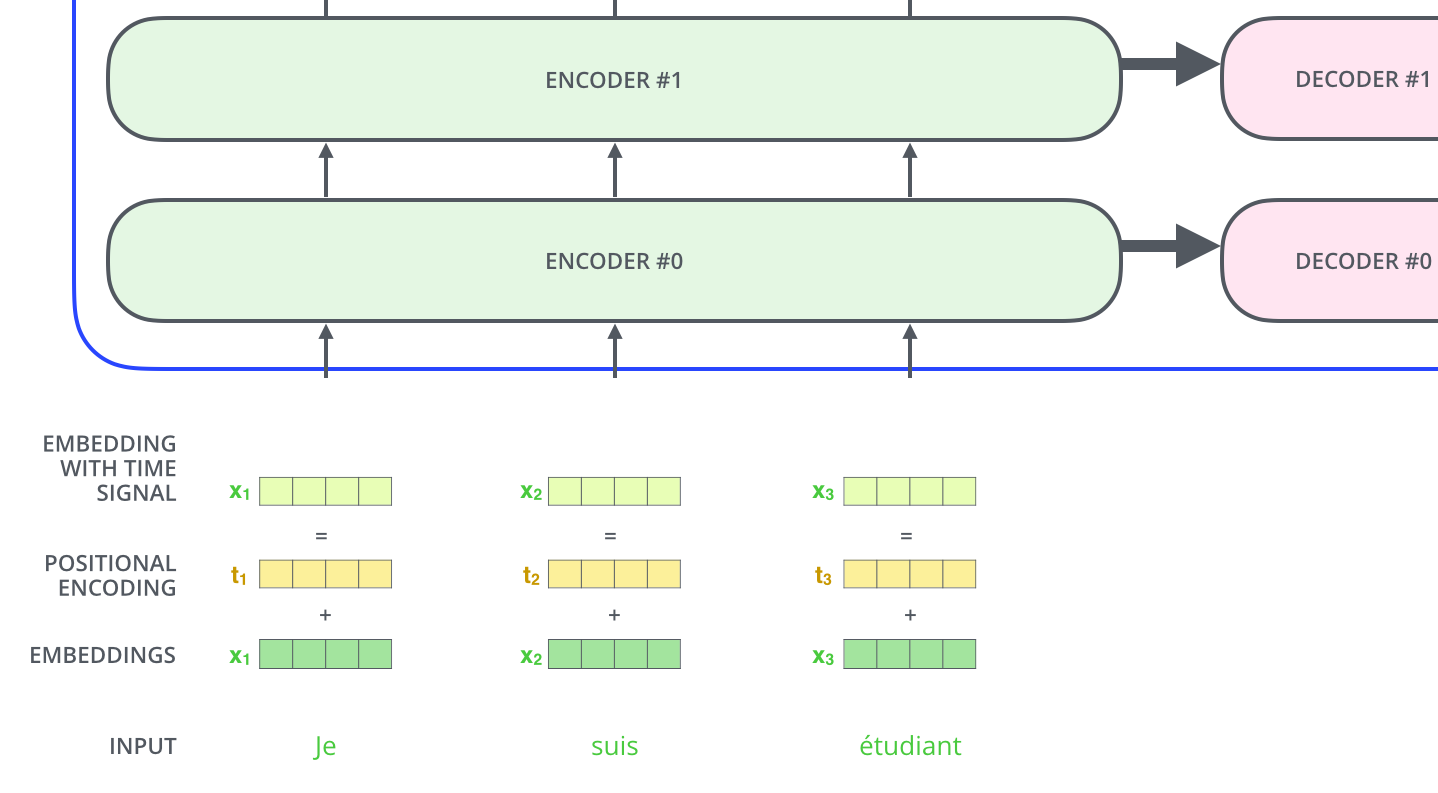
中间部分的 Transformer 可以拆分为 2 部分:左边是编码部分(encoding component),右边是解码部分(decoding component)。
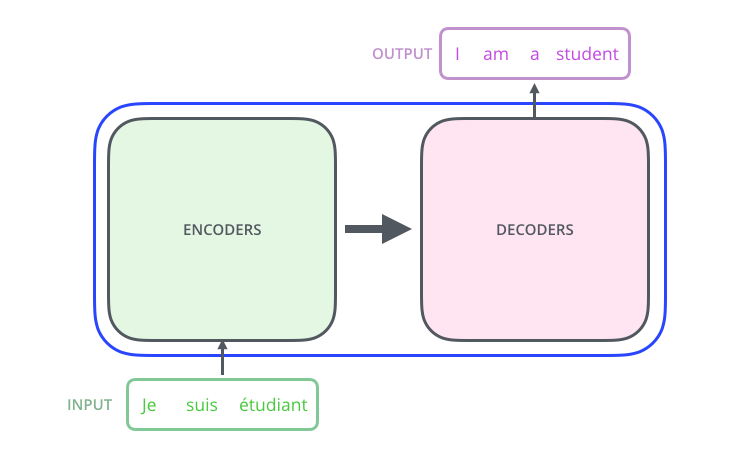
其中编码部分是多层的编码器(Encoder)组成(Transformer 的论文中使用了 6 层编码器,这里的层数 6 并不是固定的,你也可以根据实验效果来修改层数)。同理,解码部分也是由多层的解码器(Decoder)组成(论文里也使用了 6 层的解码器)。
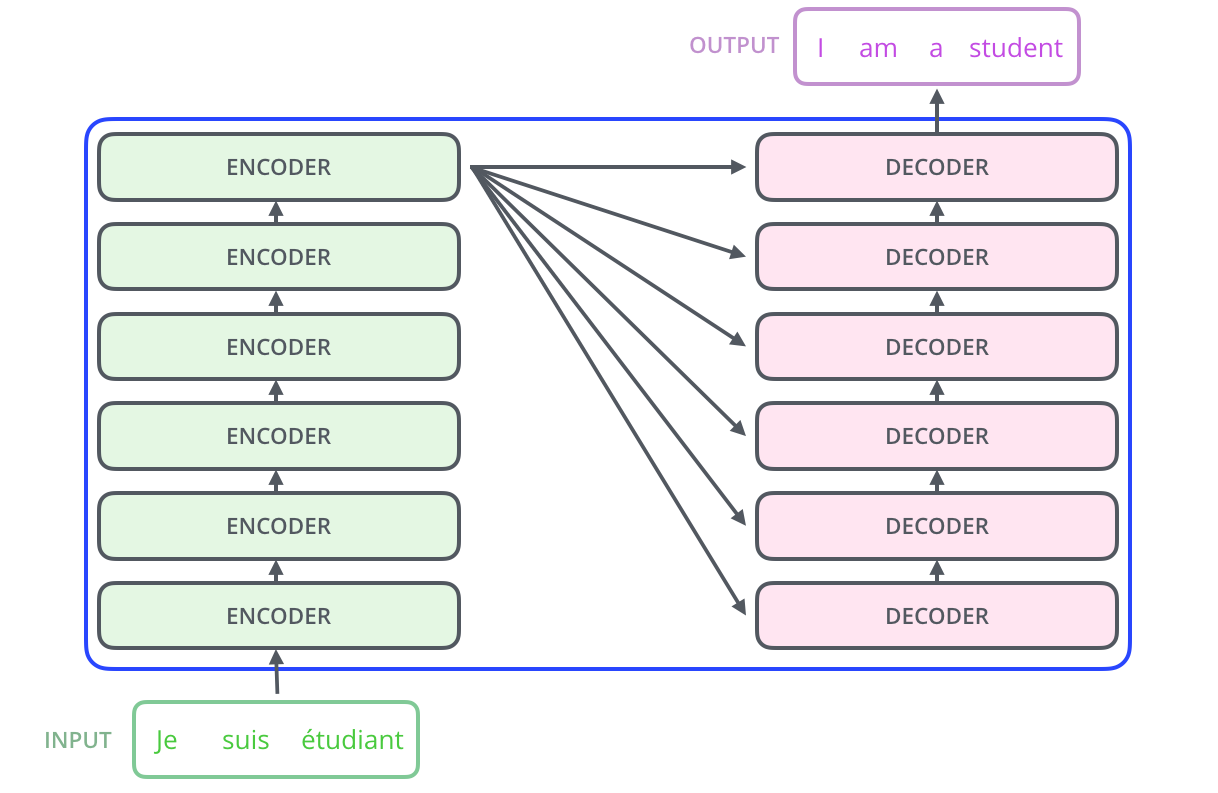
每一个Encoder 在结构上都是一样的,但它们的权重参数是不同的。每一个Encoder里面,可以分为 2 层
- Self-Attention Layer
- Feed Forward Neural Network(前馈神经网络,缩写为 FFNN)
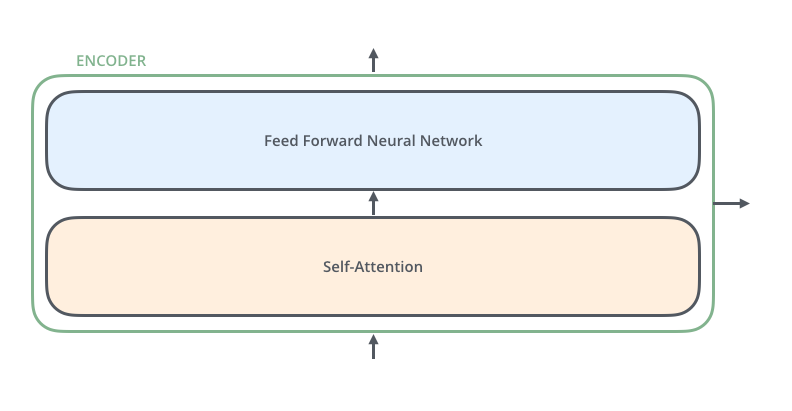
输入Encoder的文本数据,首先会经过一个 Self Attention 层,这个层处理一个词的时候,不仅会使用这个词本身的信息,也会使用句子中其他词的信息(你可以类比为:当我们翻译一个词的时候,不仅会只关注当前的词,也会关注这个词的上下文的其他词的信息)。
接下来,Self Attention 层的输出会经过前馈神经网络。同理,Decoder也具有这两层,但是这两层中间还插入了一个 Encoder-Decoder Attention 层,这个层能帮助Decoder聚焦于输入句子的相关部分(类似于 seq2seq 模型 中的 Attention)。
2. 从细节来理解Transformer
2.1 Embedding
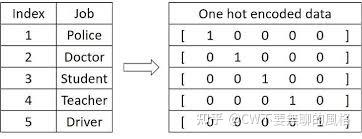
2.1.1 One-Hot Encoding
在 CV 中,我们通常将输入图片转换为4维(batch, channel, height, weight)张量来表示;而在 NLP 中,可以将输入单词用 One-Hot 形式编码成序列向量。向量长度是预定义的词汇表中拥有的单词量,向量在这一维中的值只有一个位置是1,其余都是0,1对应的位置就是词汇表中表示这个单词的地方。例如词汇表中有5个词,第3个词表示“你好”这个词,那么该词对应的 one-hot 编码即为 00100(第3个位置为1,其余为0)
2.1.2 Word Embedding
One-Hot 的形式看上去很简洁,也挺美,但劣势在于它很稀疏,而且还可能很长。比如词汇表如果有 10k 个词,那么一个词向量的长度就需要达到 10k,而其中却仅有一个位置是1,其余全是0,太“浪费”!
更重要的是,这种方式无法体现出词与词之间的关系。比如 “爱” 和 “喜欢” 这两个词,它们的意思是相近的,但基于 one-hot 编码后的结果取决于它们在词汇表中的位置,无法体现出它们之间的关系。
因此,我们需要另一种词的表示方法,能够体现词与词之间的关系,使得意思相近的词有相近的表示结果,这种方法即 Word Embedding。那么应该如何设计这种方法呢?最方便的途径是设计一个可学习的权重矩阵 W,将词向量与这个矩阵进行点乘,即得到新的表示结果。
假设 “爱” 和 “喜欢” 这两个词经过 one-hot 后分别表示为 10000 和 00001,权重矩阵设计如下:
1 | |
那么两个词点乘后的结果分别是 [w00, w01, w02] 和 [w40, w41, w42],在网络学习过程中(这两个词后面通常都是接主语,如“你”,“他”等,或者在翻译场景,它们被翻译的目标意思也相近,它们要学习的目标一致或相近),权重矩阵的参数会不断进行更新,从而使得 [w00, w01, w02] 和 [w40, w41, w42] 的值越来越接近。
另一方面,对于以上这个例子,我们还把向量的维度从5维压缩到了3维。因此,word embedding 还可以起到降维的效果。

2.2 Transformer的输入
和通常的 NLP 任务一样,我们首先会使用词嵌入算法(embedding algorithm),将每个词转换为一个词向量。实际中向量一般是 256 或者 512 维。为了简化起见,这里将每个词的转换为一个 4 维的词向量。
那么整个输入的句子是一个向量列表,其中有 3 个词向量。在实际中,每个句子的长度不一样,我们会取一个适当的值,作为向量列表的长度。如果一个句子达不到这个长度,那么就填充全为 0 的词向量;如果句子超出这个长度,则做截断。句子长度是一个超参数,通常是训练集中的句子的最大长度。

Encoder接收的输入都是一个向量列表,输出也是大小同样的向量列表,然后接着输入下一个Encoder。
第一个Encoder的输入是词向量,而后面的Encoder的输入是上一个Encoder的输出。
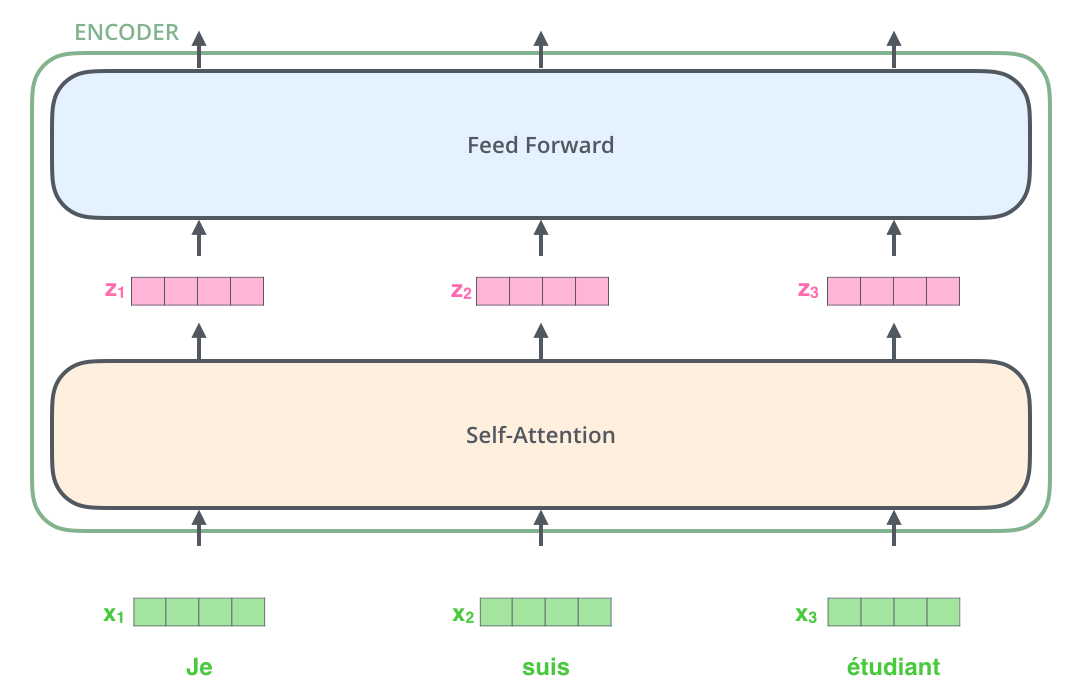
2.3 Encoder
上面我们提到,一个Encoder接收的输入是一个向量列表,它会把向量列表输入到 Self Attention 层,然后经过 feed-forward neural network (前馈神经网络)层,最后得到输出,传入下一个Encoder。
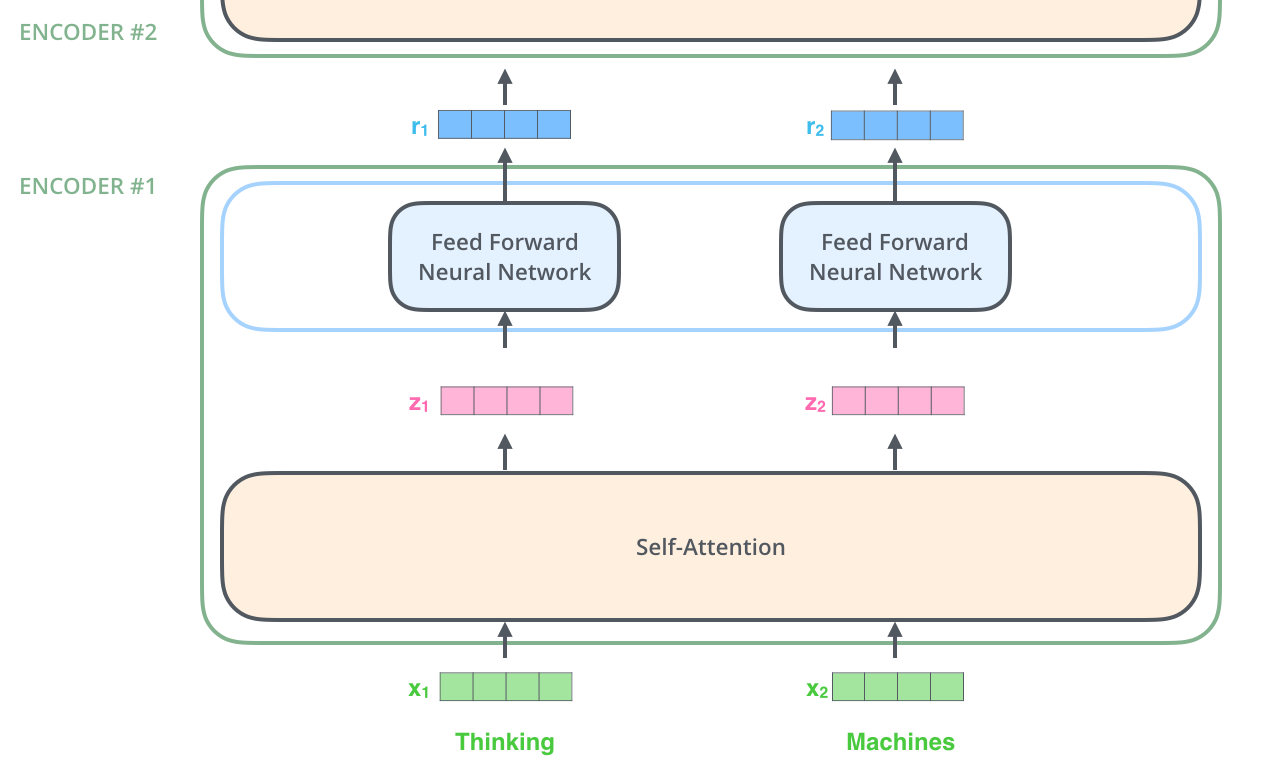
每个位置的词都经过 Self Attention 层,得到的每个输出向量都单独经过前馈神经网络层,每个向量经过的前馈神经网络都是一样的
3. Self-Attention整体理解
假设我们想要翻译的句子是:
The animal didn’t cross the street because it was too tired
这个句子中的it是一个指代词,那么it指的是什么呢?它是指animal还是street?这个问题对人来说,是很简单的,但是对算法来说并不是那么容易。当模型在处理(翻译)it的时候,Self Attention机制能够让模型把it和animal关联起来。
同理,当模型处理句子中的每个词时,Self Attention机制使得模型不仅能够关注这个位置的词,而且能够关注句子中其他位置的词,作为辅助线索,进而可以更好地编码当前位置的词。
如果你熟悉 RNN,回忆一下:RNN 在处理一个词时,会考虑前面传过来的hidden state,而hidden state就包含了前面的词的信息。而 Transformer 使用Self Attention机制,会把其他单词的理解融入处理当前的单词。
4. Self-Attention的细节
4.1 计算Query向量、Key向量、Value向量
计算 Self Attention 的第 1 步是:对输入编码器的每个词向量,都创建 3 个向量,分别是:Query 向量,Key 向量,Value 向量。这 3 个向量是词向量分别和 3 个矩阵相乘得到的,而这个矩阵是我们要学习的参数。注意,这 3 个新得到的向量一般比原来的词向量的长度更小。它们的维度为 64,而词向量的维度为 512。
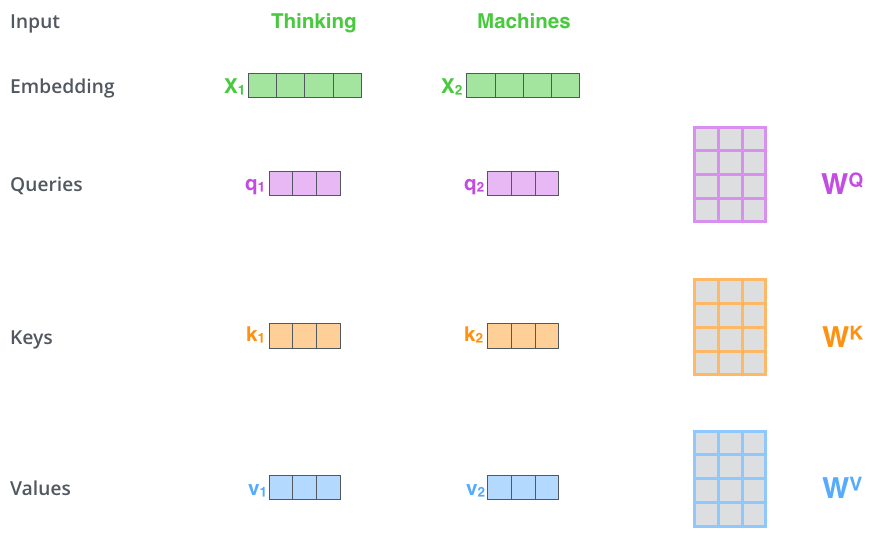
上图中,有两个词向量:Thinking 的词向量 x1 和 Machines 的词向量 x2。以 x1 为例,x1 乘以 WQ 得到 q1,q1 就是 x1 对应的 Query 向量。同理,x1 乘以 WK 得到 k1,k1 是 x1 对应的 Key 向量;x1 乘以 WV 得到 v1,v1 是 X1 对应的 Value 向量。
4.2 计算Attention Score
第 2 步,是计算 Attention Score(注意力分数)。假设我们现在计算第一个词Thinking的 Attention Score(注意力分数),需要根据Thinking这个词,对句子中的其他每个词都计算一个分数。这些分数决定了我们在编码Thinking这个词时,需要对句子中其他位置的每个词放置多少的注意力。
这些分数,是通过计算 “Thinking” 对应的 Query 向量q1和其他位置的每个词的 Key 向量k的点积而得到的。如果我们计算句子中第一个位置单词的 Attention Score(注意力分数),那么第一个分数就是 q1 和 k1 的内积,第二个分数就是 q1 和 k2 的点积。
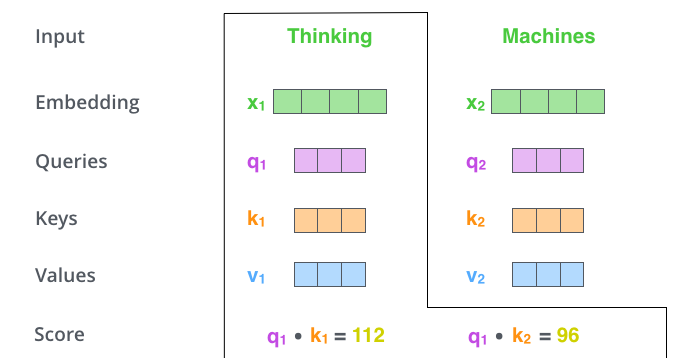
第 3 步就是把每个分数除以8(是 Key 向量的维度64的平方根)。也可以除以其他数,但这个是默认值,除以一个数是为了在反向传播时,求取梯度更加稳定。
第 4 步,接着把这些分数经过一个 Softmax 层,Softmax可以将分数归一化,这样使得分数都是正数并且加起来等于 1。
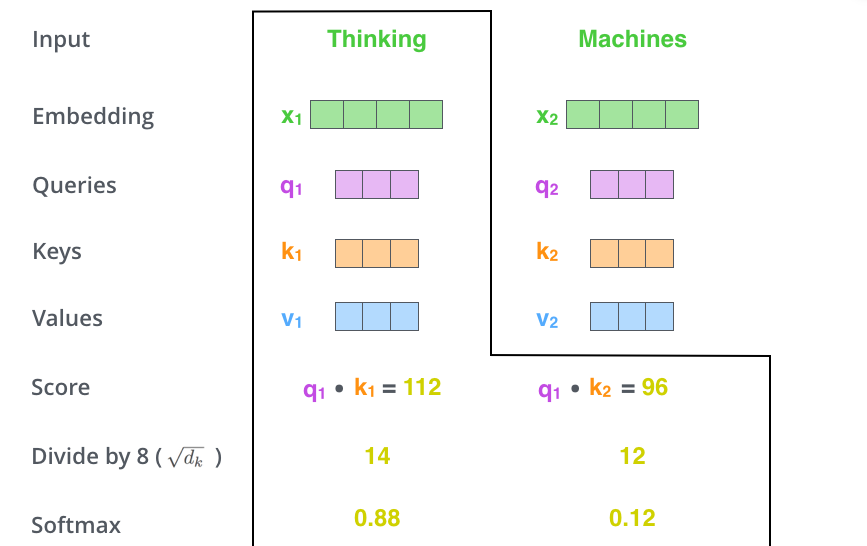
这些分数决定了在编码当前位置(这里的例子是第一个位置)的词时,对所有位置的词分别有多少的注意力。很明显,在上图的例子中,当前位置(这里的例子是第一个位置)的词会有最高的分数,但有时,关注到其他位置上相关的词也很有用。
第 5 步,得到每个位置的分数后,将每个分数分别与每个 Value 向量相乘。这种做法背后的直觉理解就是:对于分数高的位置,相乘后的值就越大,我们把更多的注意力放到了它们身上;对于分数低的位置,相乘后的值就越小,这些位置的词可能是相关性不大的,这样我们就忽略了这些位置的词。
第 6 步是把上一步得到的向量相加,就得到了 Self Attention 层在这个位置(这里的例子是第一个位置)的输出。
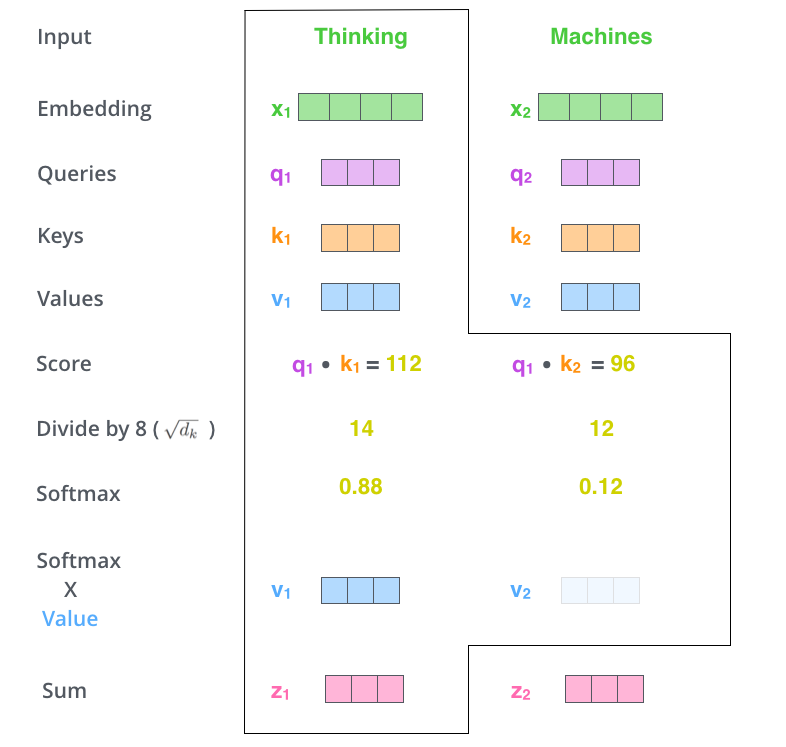
上面这张图,包含了 Self Attention 的全过程,最终得到的当前位置(这里的例子是第一个位置)的向量会输入到前馈神经网络。但这样每次只能计算一个位置的输出向量,在实际的代码实现中,Self Attention 的计算过程是使用矩阵来实现的,这样可以加速计算,一次就得到所有位置的输出向量。下面让我们来看,如何使用矩阵来计算所有位置的输出向量。
5. 使用矩阵计算Self-Attention
第一步是计算 Query,Key,Value 的矩阵。首先,我们把所有词向量放到一个矩阵 X 中,然后分别和 3 个权重矩阵相乘,得到 Q,K,V 矩阵。
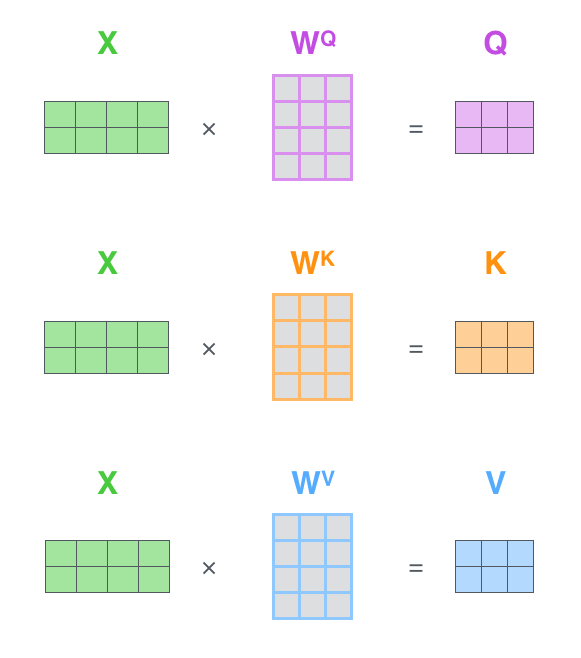
矩阵 X 中的每一行,表示句子中的每一个词的词向量,长度是 512。Q,K,V 矩阵中的每一行对应行的词向量表示的 Query 向量,Key 向量,Value 向量,向量长度是 64。
接着,由于我们使用了矩阵来计算,我们可以把上面的第 2 步到第 6 步压缩为一步,直接得到 Self Attention 的输出。
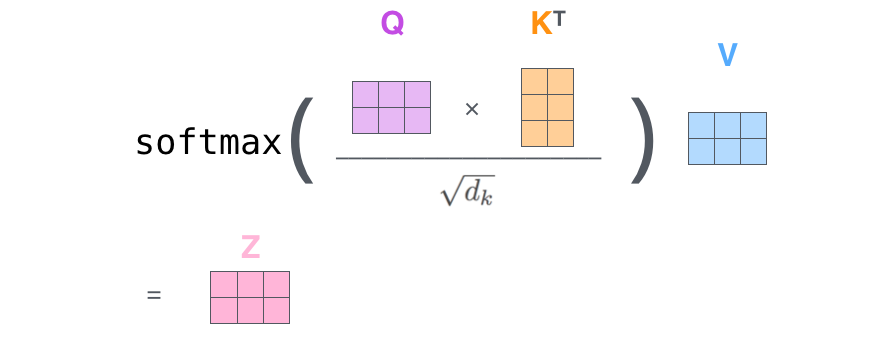
6. 多头注意力机制(multi-head attention)
Transformer 的论文通过增加多头注意力机制(一组注意力称为一个 attention head),进一步完善了 Self Attention 层。这种机制从如下两个方面增强了 attention 层的能力:
- 它扩展了模型关注不同位置的能力。在上面的例子中,第一个位置的输出 z1 包含了句子中其他每个位置的很小一部分信息,但 z1 可能主要是由第一个位置的信息决定的。当我们翻译句子:The animal didn’t cross the street because it was too tired时,我们想让机器知道其中的it指代的是什么。这时,多头注意力机制会有帮助。
- 多头注意力机制赋予 attention 层多个“子表示空间”。下面我们会看到,多头注意力机制会有多组的权重矩阵(在 Transformer 的论文中,使用了 8 组注意力(attention heads))。每一组注意力的的权重矩阵都是随机初始化的。经过训练之后,每一组注意力可以看作是把输入的向量映射到一个”子表示空间“。
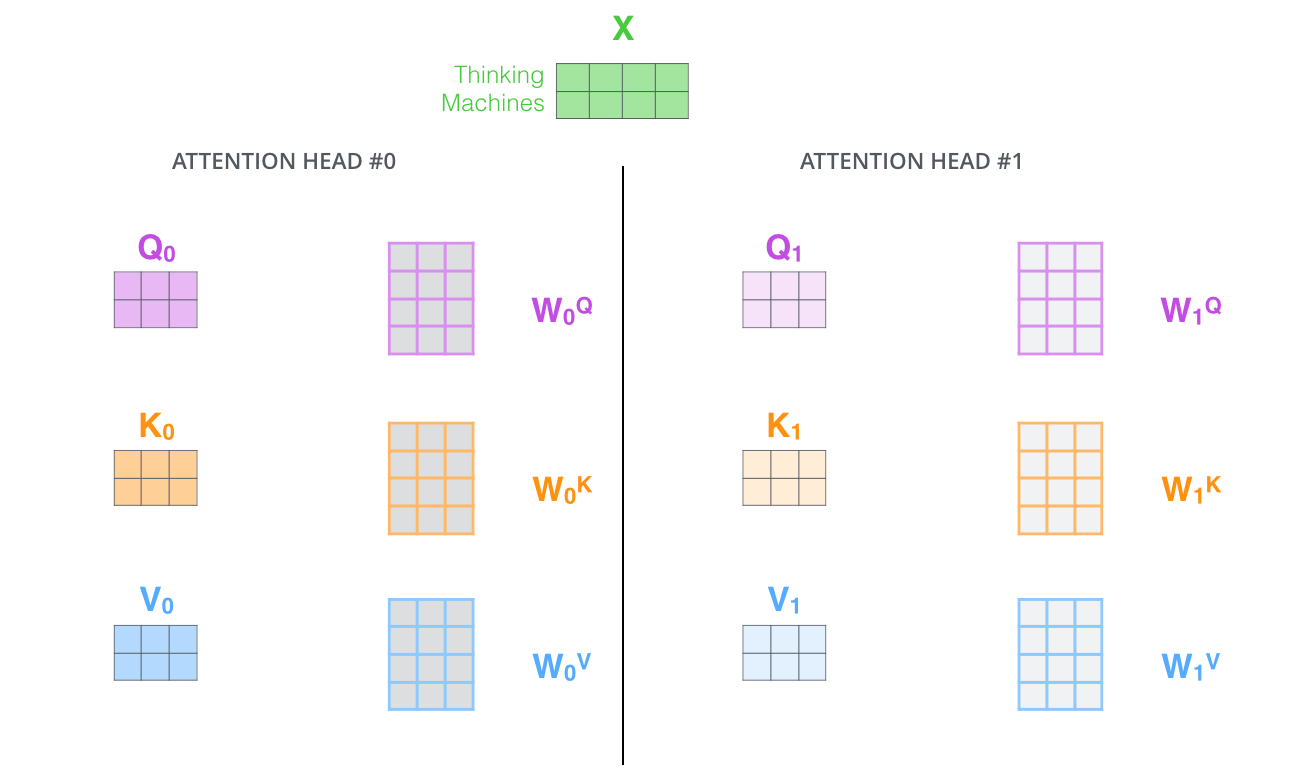
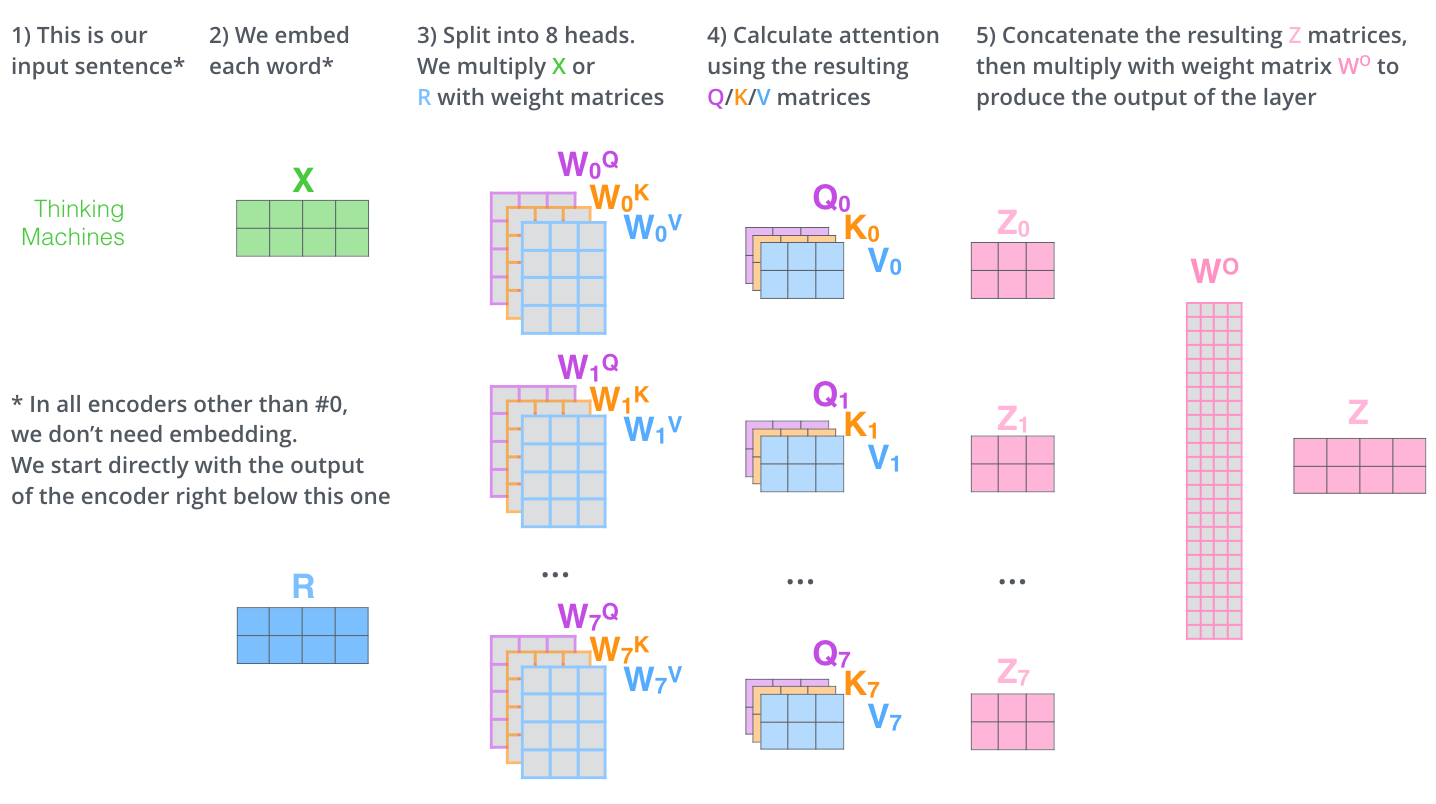
在多头注意力机制中,我们为每组注意力维护单独的 WQ, WK, WV 权重矩阵。将输入 X 和每组注意力的WQ, WK, WV 相乘,得到 8 组 Q, K, V 矩阵。
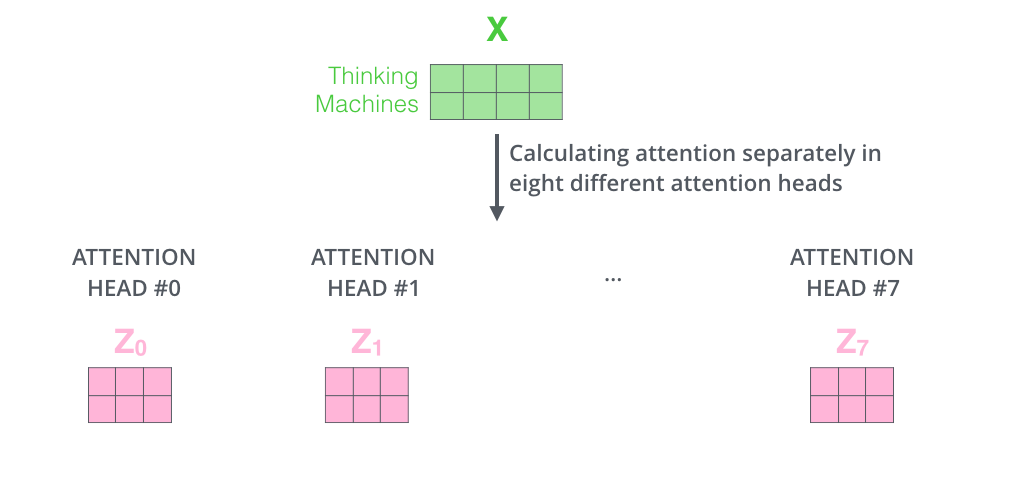
接着,我们把每组 K, Q, V 计算得到每组的 Z 矩阵,就得到 8 个 Z 矩阵。
接下来就有点麻烦了,因为前馈神经网络层接收的是 1 个矩阵(其中每行的向量表示一个词),而不是 8 个矩阵。所以我们需要一种方法,把 8 个矩阵整合为一个矩阵。我们把矩阵拼接起来,然后和另一个权重矩阵WO相乘。
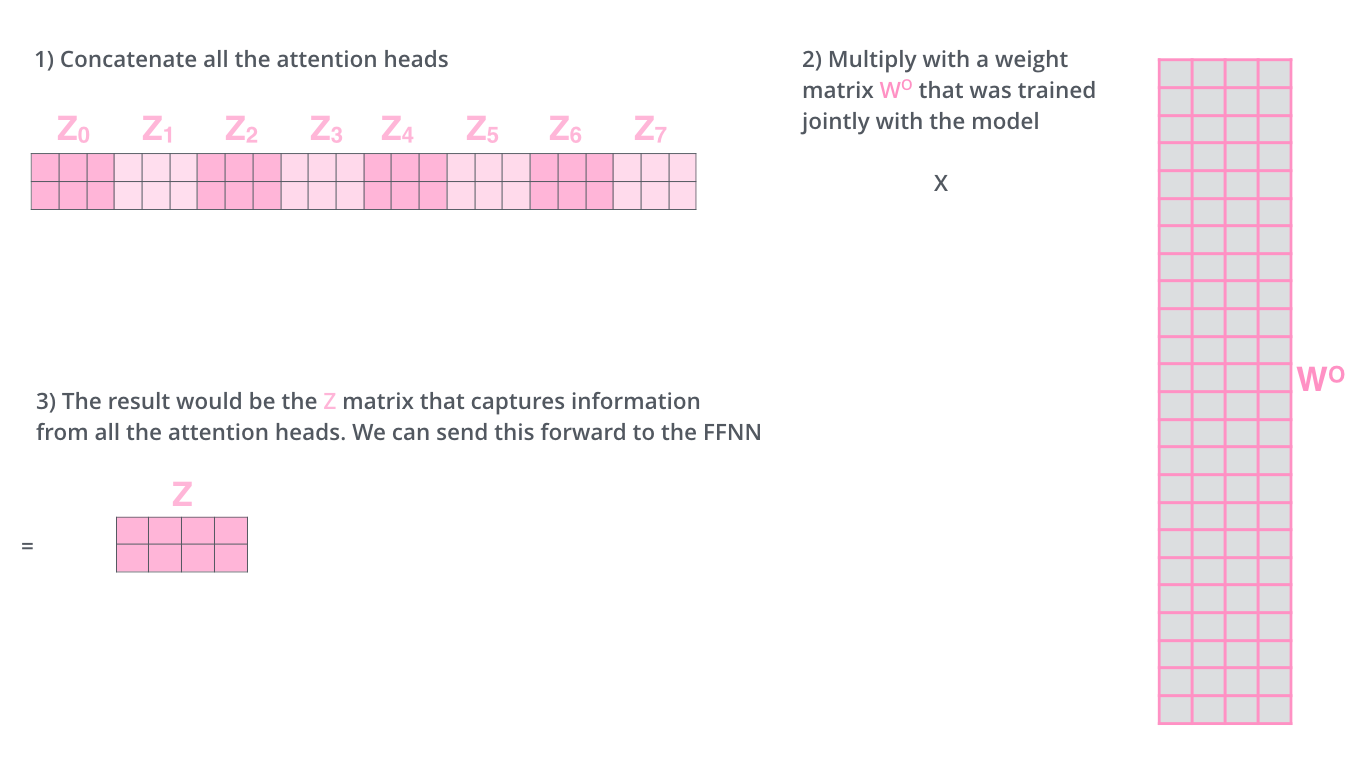
这就是多头注意力的全部内容。
既然我们已经谈到了多头注意力,现在让我们重新回顾之前的翻译例子,看下当我们编码单词it时,不同的 attention heads (注意力头)关注的是什么部分。

![]()
当我们编码单词”it”时,其中一个 attention head 最关注的是”the animal”,另外一个 attention head 关注的是”tired”。因此在某种意义上,”it”在模型中的表示,融合了”animal”和”tired”的部分表达。
7. 使用位置编码来表示序列的顺序(Position Embedding)
到目前为止,我们阐述的模型中缺失了一个东西,那就是表示序列中单词顺序的方法。由于 Transformer 是并行地(相比于RNN,无法做并行)处理句子中的所有词,也就是说经过上面的Word Embedding后,词与词之间不存在顺序关系(打乱一句话,这句话里的每个词的词向量依然不会变),因此需要加入词在句子中的位置信息,结合了这种方式的词嵌入就是 Position Embedding 了。
为了解决这个问题,Transformer 模型对每个输入的向量都添加了一个向量。这些向量遵循模型学习到的特定模式,有助于确定每个单词的位置,或者句子中不同单词之间的距离。这种做法背后的直觉是:将这些表示位置的向量添加到词向量中,得到了新的向量,这些新向量映射到 Q/K/V,然后计算点积得到 attention 时,可以提供有意义的信息。
那么具体该怎么做?我们通常容易想到两种方式:
1、通过网络来学习;
2、预定义一个函数,通过函数计算出位置信息;
Transformer 的作者对以上两种方式都做了探究,发现最终效果相当,于是采用了第2种方式,从而减少模型参数量,同时还能适应即使在训练集中没有出现过的句子长度。
计算位置信息的函数计算公式如下:
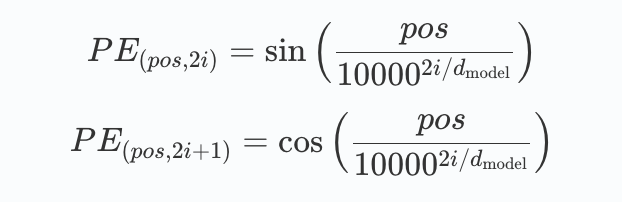
pos 代表的是词在句子中的位置,d_model 是词向量的维度(通常经过 word embedding 后是512),2i 代表的是 d 中的偶数维度,(2i + 1) 则代表的是奇数维度,这种计算方式使得每一维都对应一个正弦曲线。
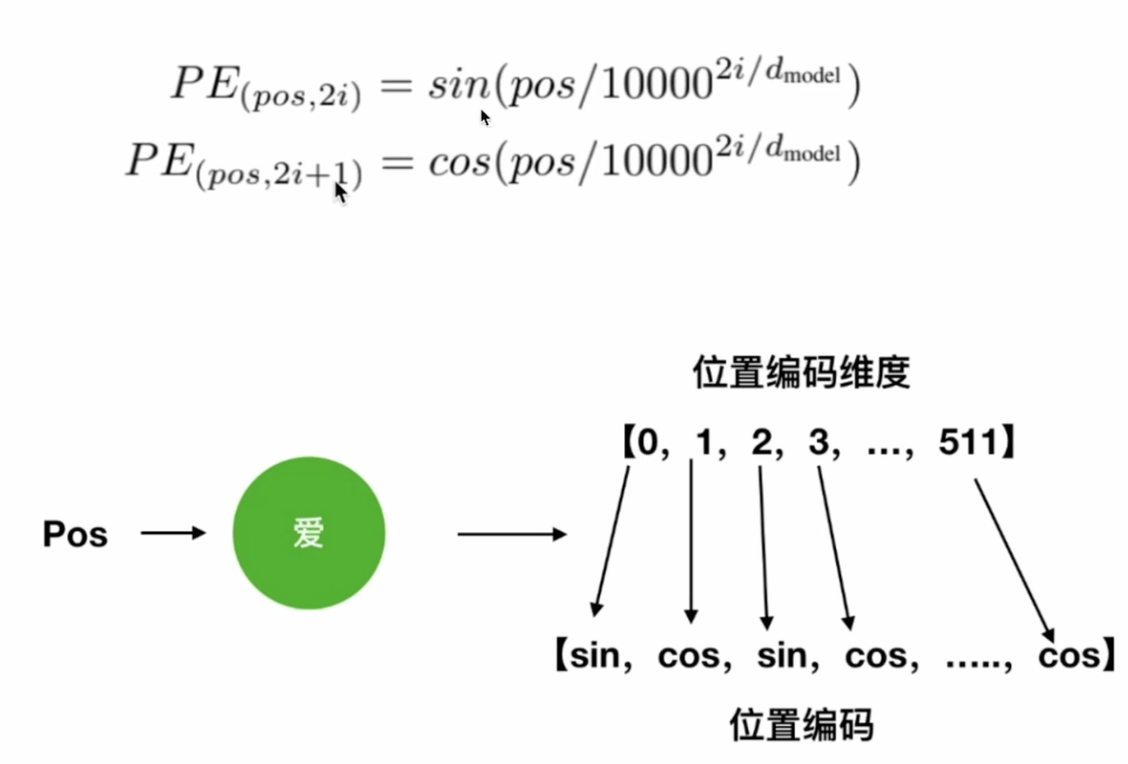
举个例子:对于一句话“我爱你”,“我”,“爱”,“你”这三个词经过Word Embedding后得到三个词向量,均为1* d_model维,则“爱”的pos为2:
- 为何使用三角函数呢?
- 由于三角函数的性质: sin(a+b) = sin(a)cos(b) + cos(a)sin(b)、 cos(a+b) = cos(a)cos(b) - sin(a)sin(b),于是,对于位置 pos+k 处的信息,可以由 pos 位置计算得到,作者认为这样可以让模型更容易地学习到位置信息。
- 为何使用这种方式编码能够代表不同位置信息呢?
- 由公式可知,每一维 i 都对应不同周期的正余弦曲线: i=0 时是周期为 2π 的 sin 函数, i=1 时是周期为 2π 的cos 函数..对于不同的两个位置 pos1 和 pos2 ,若它们在某一维 i 上有相同的编码值,则说明这两个位置的差值等于该维所在曲线的周期,即 |pos1−pos2|=Ti 。而对于另一个维度 j(j≠i) ,由于 Tj≠Ti ,因此 pos1 和 pos2 在这个维度 j 上的编码值就不会相等,对于其它任意 k∈{0,1,2,..,d−1};k≠i 也是如此。
8. 残差连接
在我们继续讲解之前,Encoder结构中有一个需要注意的细节是:编码器的每个子层(Self Attention 层和 FFNN)都有一个残差连接和层标准化(layer-normalization)。
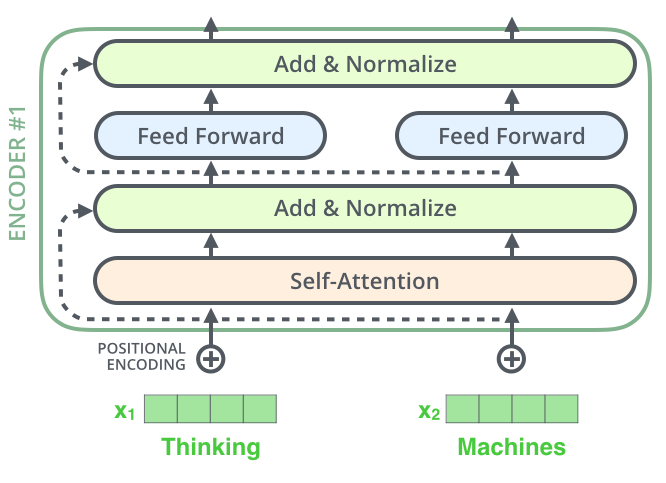
将 Self-Attention 层的层标准化(layer-normalization)和向量都进行可视化,如下所示:
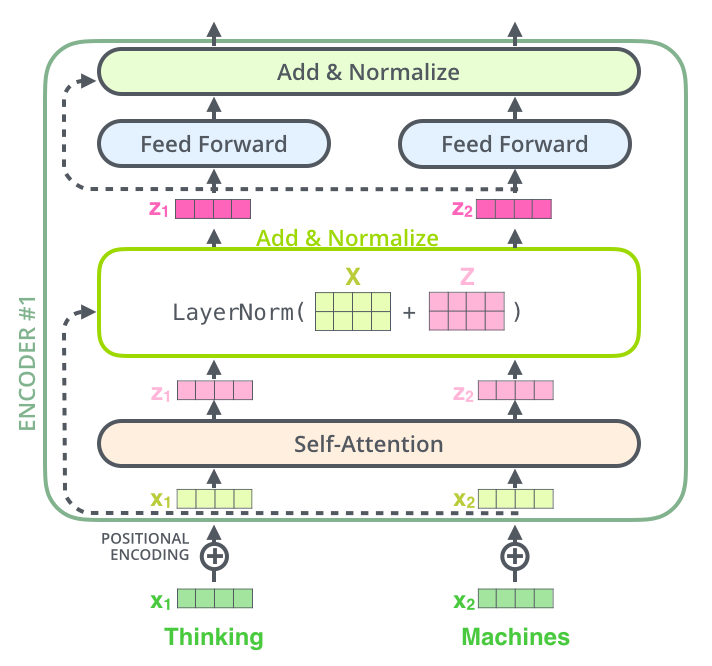
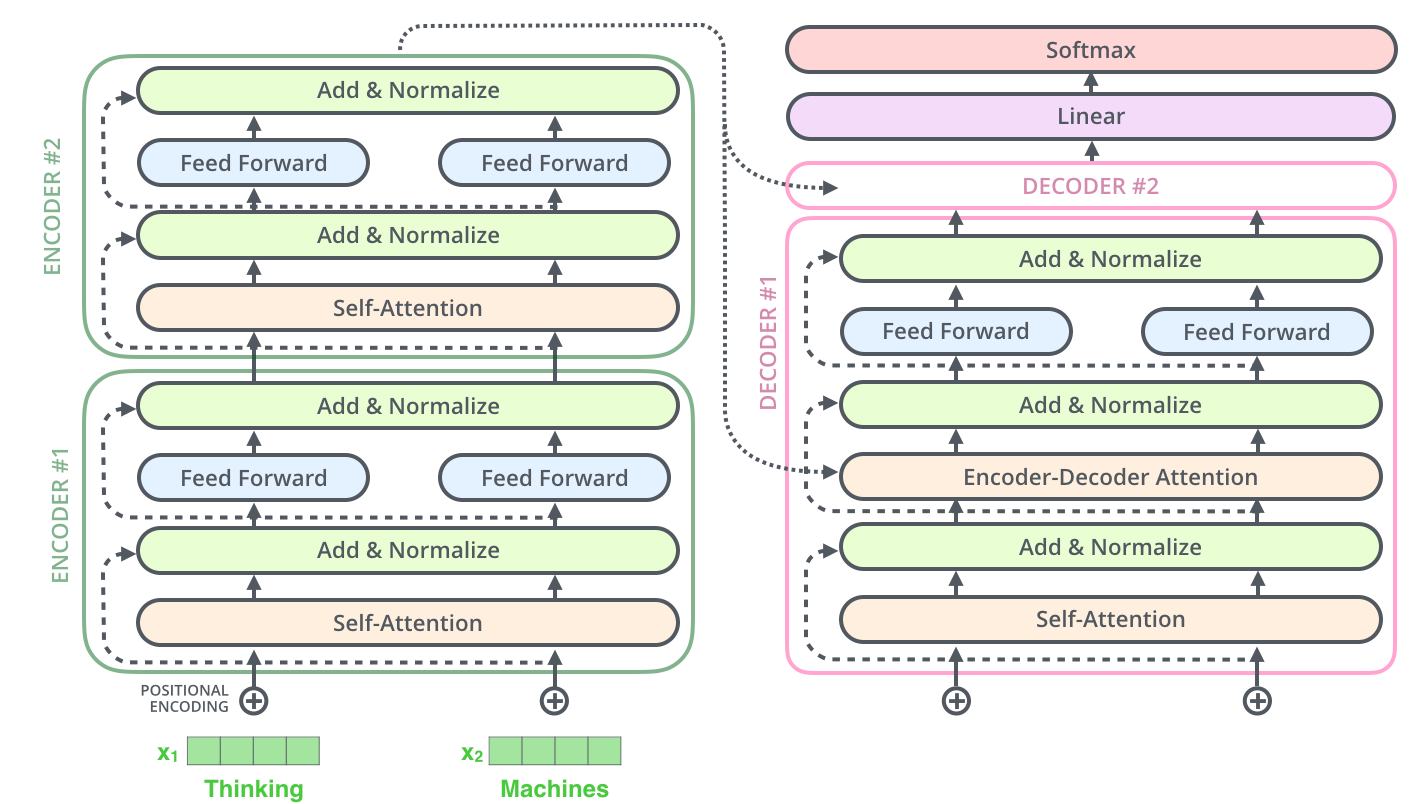
在解码器的子层里面也有层标准化(layer-normalization)。假设一个 Transformer 是由 2 层Encoder和两层Decoder组成的,如下图所示。
9. Feed Forward
Feed Forward 层比较简单,是一个两层的全连接层,第一层的激活函数为 Relu,第二层不使用激活函数,对应的公式如下:
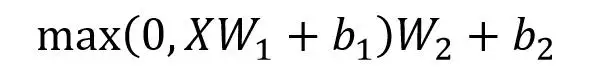
X是输入,Feed Forward 最终得到的输出矩阵的维度与X一致
10. Encoder结构实现
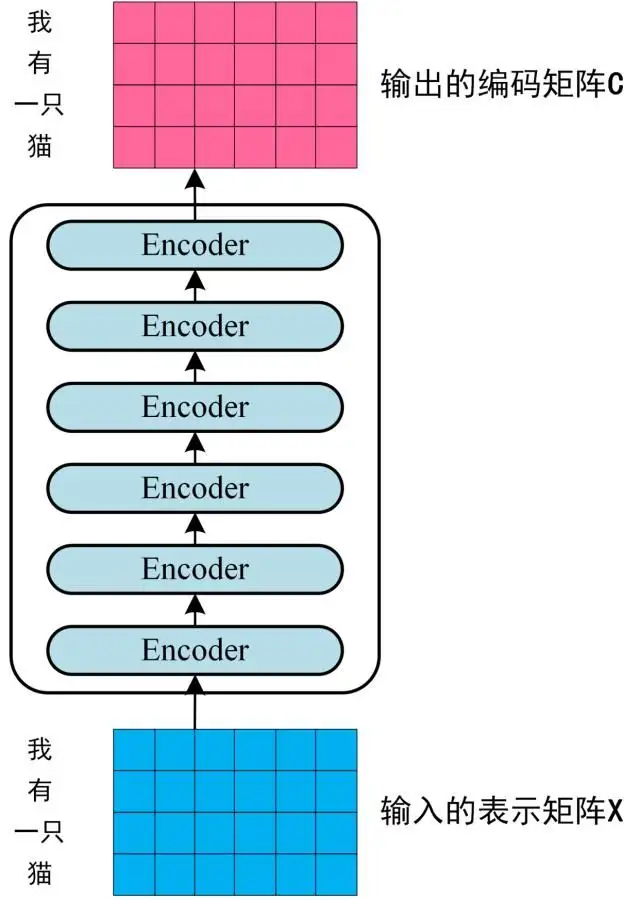
通过上面描述的Multi-Head Attention、Feed Forward、Add&Norm,就可以构造出一个Encoder Block,多个Encoder Block叠加就可以组成Encoder
第一个 Encoder block 的输入为句子单词的表示向量矩阵,后续 Encoder block 的输入是前一个 Encoder block 的输出,最后一个 Encoder block 输出的矩阵就是编码信息矩阵 C,这一矩阵后续会用到 Decoder 中。
11. Decoder
现在我们已经介绍了Decoder中的大部分概念,我们也基本知道了Decoder的原理。现在让我们来看下, Encoder和Decoder是如何协同工作的。
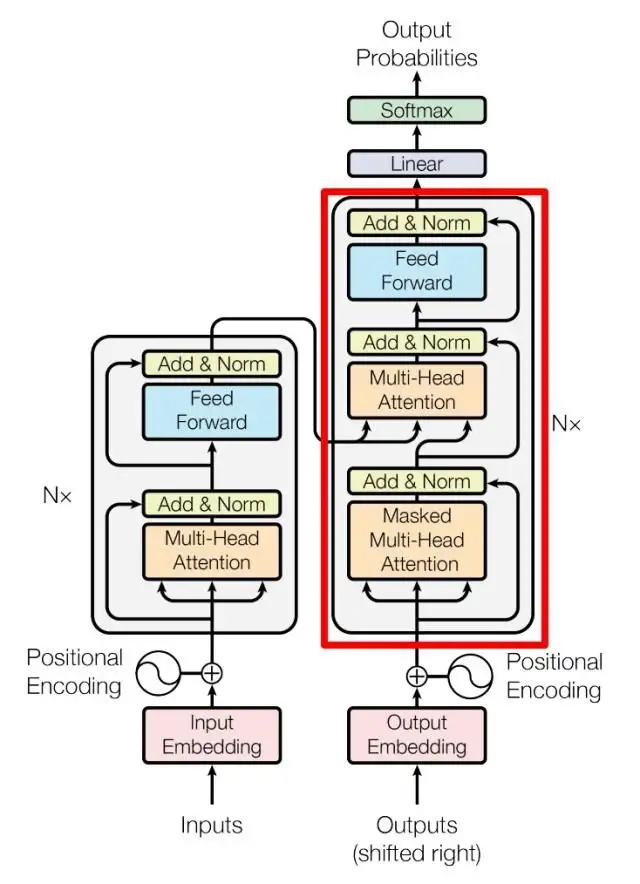
上图红色部分为 Transformer 的 Decoder block 结构,与 Encoder block 相似,但是存在一些区别:
包含两个 Multi-Head Attention 层。
第一个 Multi-Head Attention 层采用了 Masked 操作。
第二个 Multi-Head Attention 层的K、V矩阵使用 Encoder 的编码信息矩阵C进行计算,而Q使用上一个 Decoder block 的输出计算。
最后有一个 Softmax 层计算下一个翻译单词的概率。
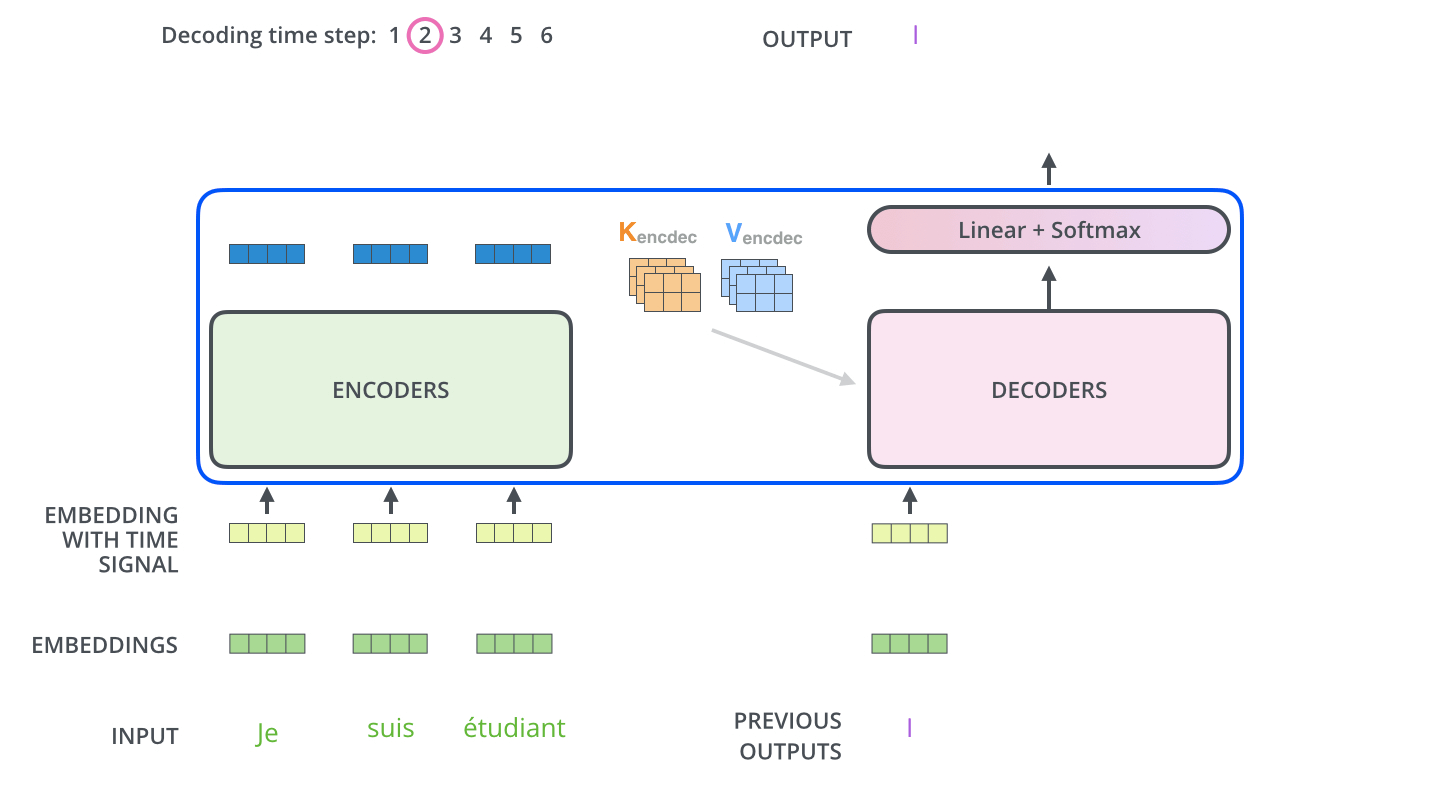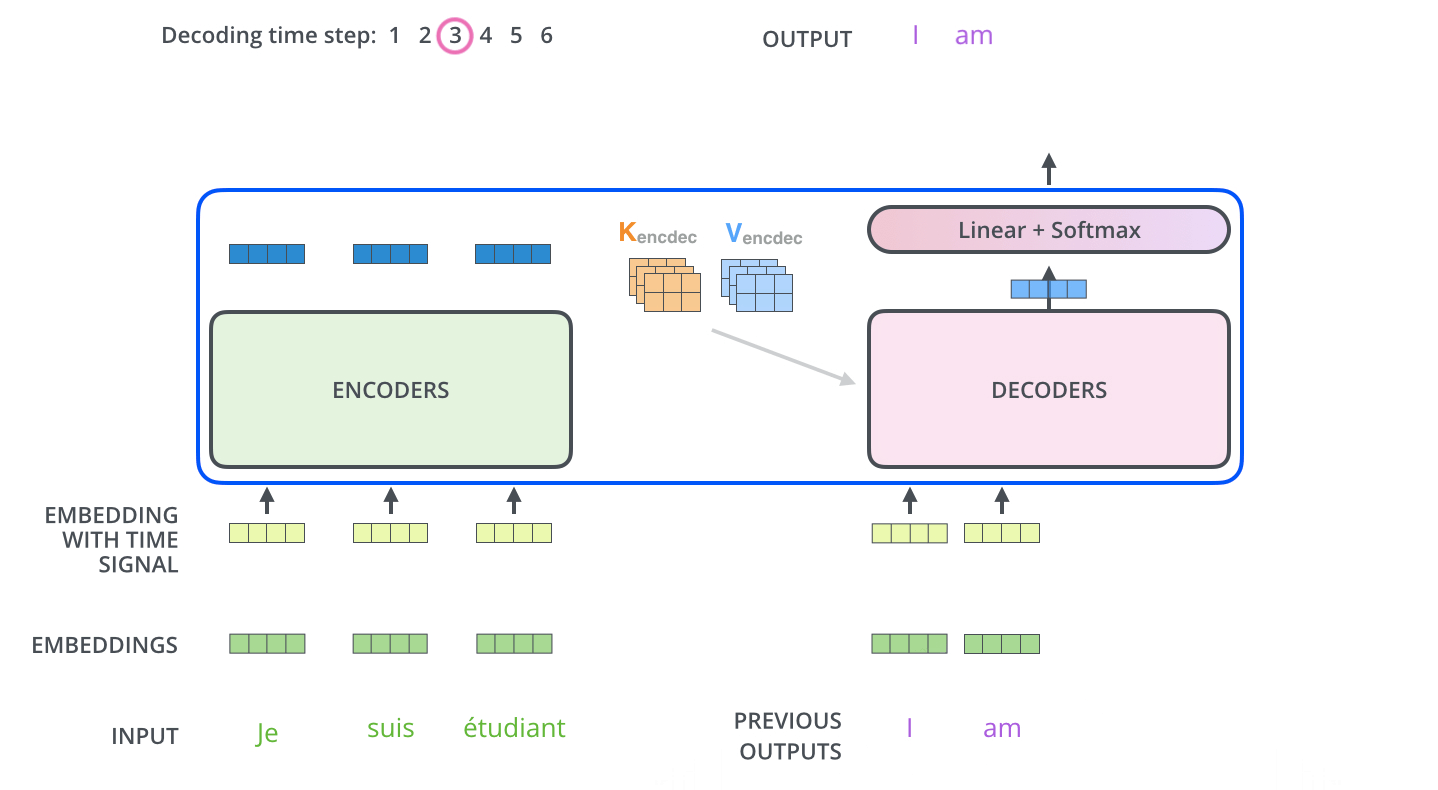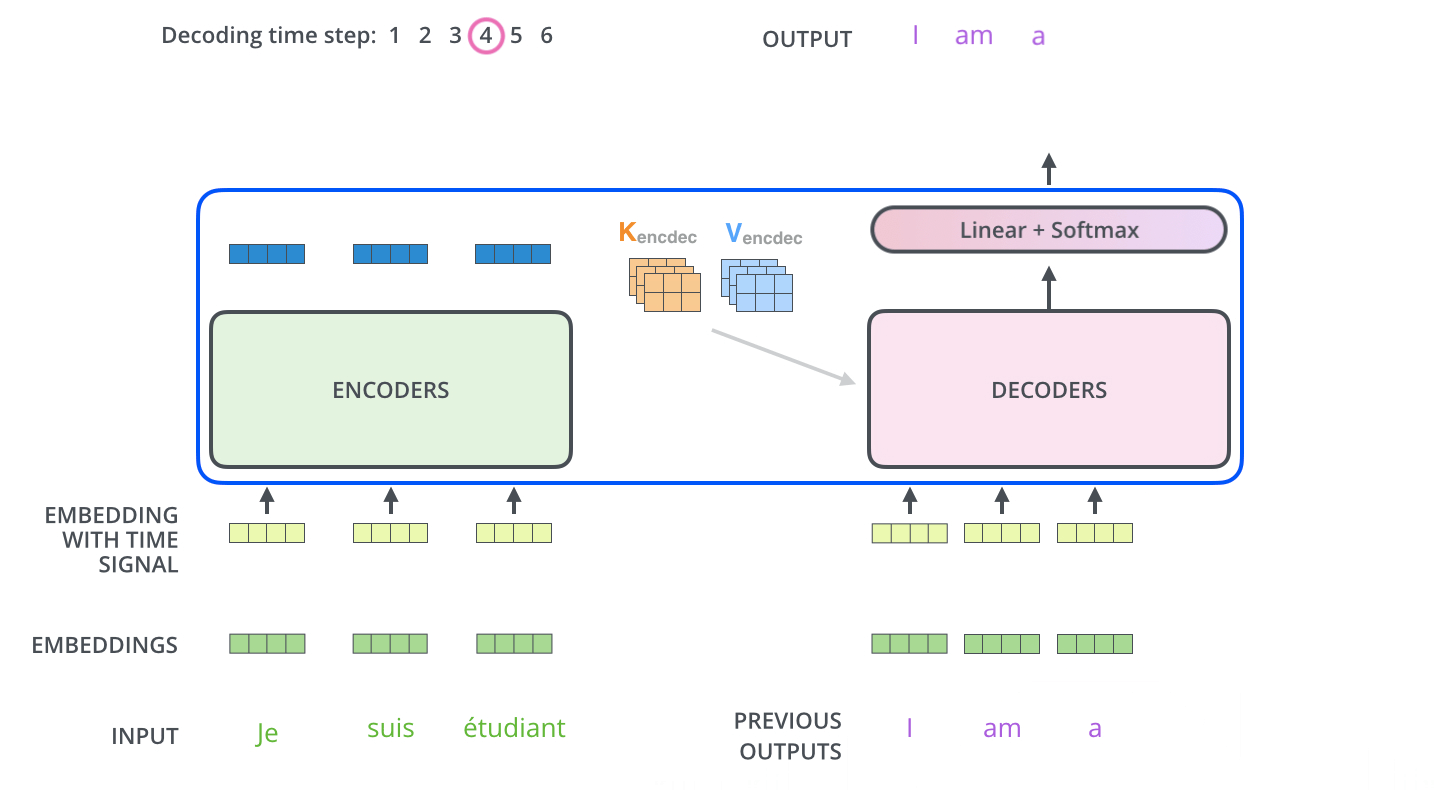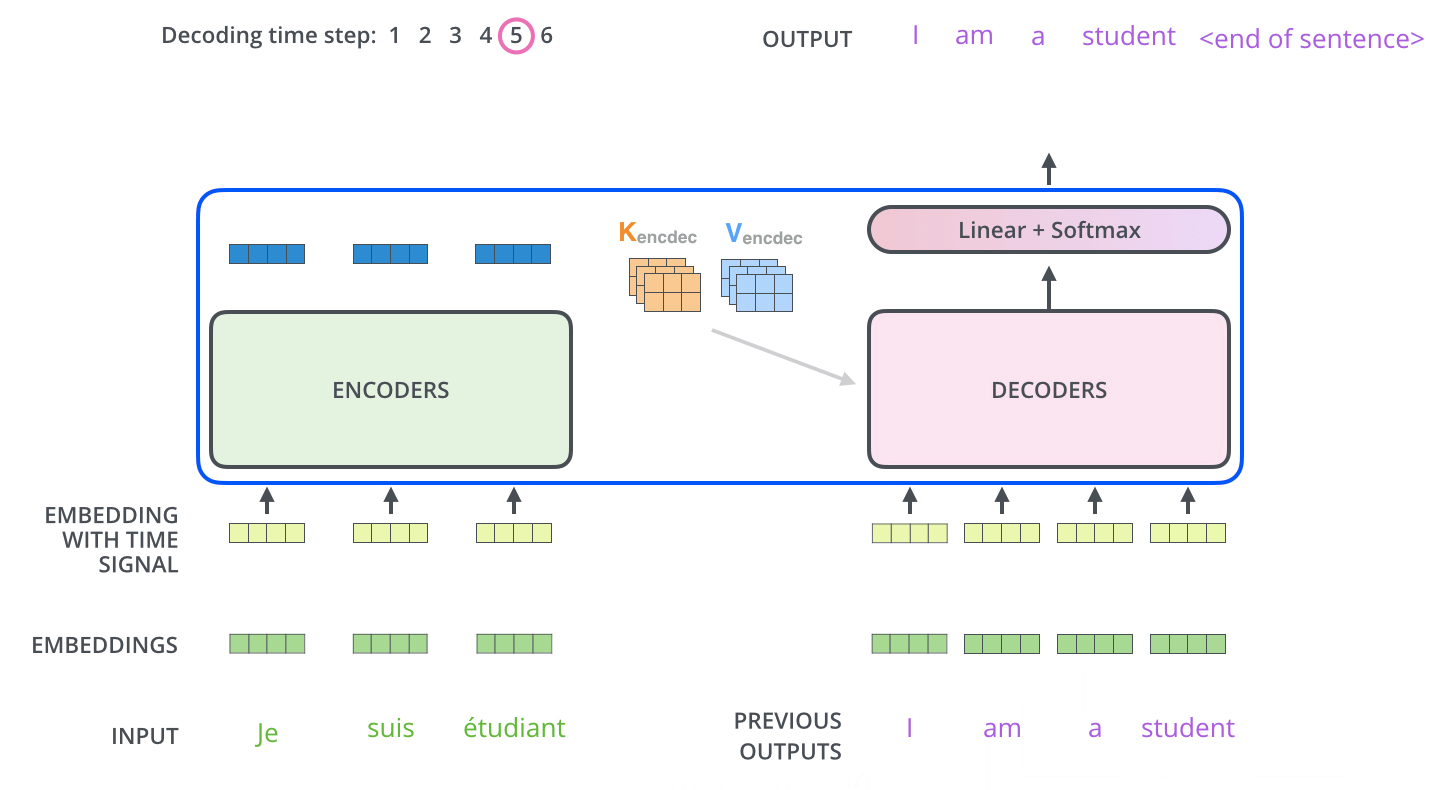
11.1 训练过程
- 初始decoder的time step为1时(也就是第一次接收输入),其输入为一个特殊的token,可能是目标序列开始的token(如
),也可能是源序列结尾的token(如 ),也可能是其它视任务而定的输入等等,不同源码中可能有微小的差异,其目标则是预测翻译后的第1个单词(token)是什么; - 2.然后
和预测出来的第1个单词一起,再次作为decoder的输入,得到第2个预测单词;3后续依此类推;
具体的例子如下:
样本:“我/爱/机器/学习”和 “i/ love /machine/ learning”
训练:
- 把“我/爱/机器/学习”embedding后输入到Encoder里去,最后一层的Encoder最终输出的编码信息矩阵C,C 乘以新的参数矩阵,可以作为Decoder里第二个Multi-Head Attention 层用到的K和V;
- 将
作为Decoder的初始输入,将Decoder的最大概率输出词 A1和‘i’做cross entropy计算error。 - 将
,”i” 作为Decoder的输入,将Decoder的最大概率输出词 A2 和‘love’做cross entropy计算error。 - 将
,”i”,”love” 作为Decoder的输入,将Decoder的最大概率输出词A3和’machine’ 做cross entropy计算error。 - 将
,”i”,”love “,”machine” 作为Decoder的输入,将Decoder最大概率输出词A4和‘learning’做cross entropy计算error。 - 将
,”i”,”love “,”machine”,”learning” 作为Decoder的输入,将Decoder最大概率输出词A5和终止符做cross entropy计算error。
11.2 第一个Multi-Head Attention(Masked Multi-Head Attention)
上述训练过程是挨个单词串行进行的,那么能不能并行进行呢,当然可以。可以看到上述单个句子训练时候,输入到 Decoder的分别是
1 | |
那么为何不将这些输入组成矩阵,进行输入呢?这些输入组成矩阵形式如下:
1 | |
怎么操作得到这个矩阵呢?将decoder在上述2-6步次的输入补全为一个完整的句子
1 | |
然后将上述矩阵按位乘以一个 mask矩阵
1 | |
上面操作表示成图如下:
- 和之前的 Self-Attention 一样,通过输入矩阵X(这里的输入矩阵是真解:i love machine learning的词向量)计算得到Q,K,V矩阵。然后计算Q和$K ^ { T }$ 的乘积$Q K ^ { T }$ 。
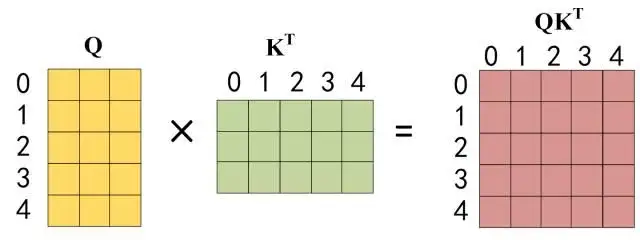
在得到$Q K ^ { T }$ 之后需要进行 Softmax,计算 attention score,我们在 Softmax 之前需要使用Mask矩阵遮挡住每一个单词之后的信息,遮挡操作如下:
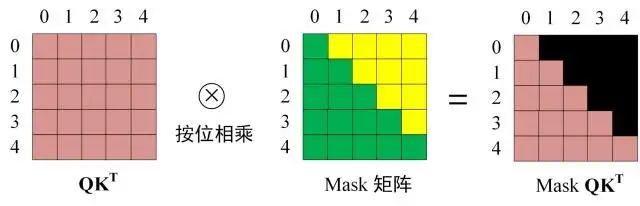
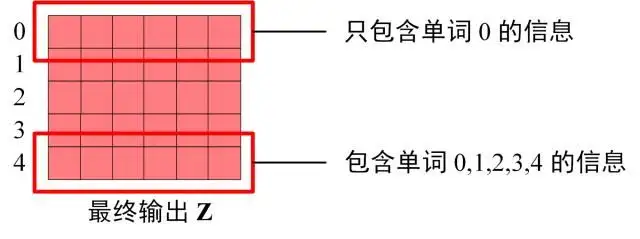
得到 Mask $Q K ^ { T }$ 之后在 Mask $Q K ^ { T }$ 上进行 Softmax,每一行的和都为 1。但是单词 0 在单词 1, 2, 3, 4 上的 attention score 都为 0。
使用 Mask $Q K ^ { T }$ 与矩阵 V相乘,得到输出 Z,则单词 1 的输出向量 $Z _ { 1 }$ 是只包含单词 1 信息的。
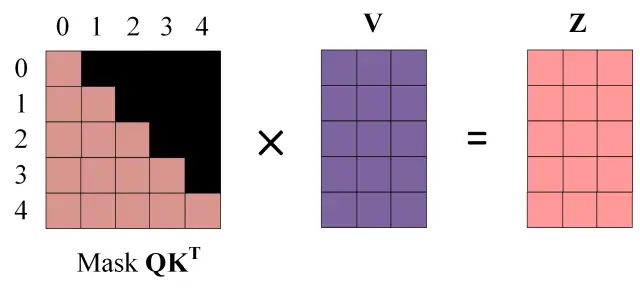
通过上述步骤就可以得到一个 Mask Self-Attention 的输出矩阵$Z _ { i }$ ,然后和 Encoder 类似,通过 Multi-Head Attention 拼接多个输出 $Z _ { i }$ 然后计算得到第一个 Multi-Head Attention 的输出Z,Z与输入X维度一样。
11.3 第二个Multi-Head Attention
Decoder block 第二个 Multi-Head Attention 变化不大, 主要的区别在于其中 Self-Attention 的 K, V矩阵不是使用 上一个 Decoder block 的输出计算的,而是使用 Encoder 的编码信息矩阵 C 计算的。
根据 Encoder 的输出 C计算得到 K, V,根据上一个 Decoder block 的输出 Z 计算 Q (如果是第一个 Decoder block 则使用输入矩阵 X 进行计算),后续的计算方法与之前描述的一致。
这样做的好处是在 Decoder 的时候,每一位单词都可以利用到 Encoder 所有单词的信息 (这些信息无需 Mask)。
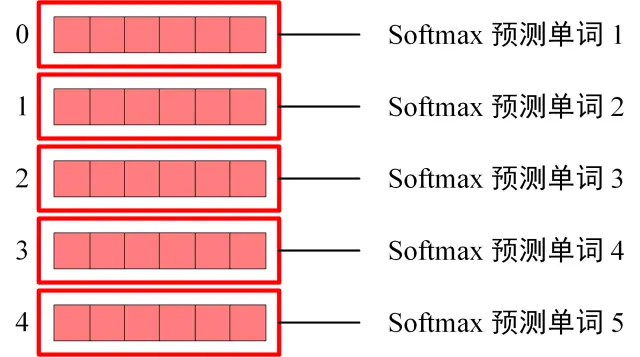
11.4 SoftMax预测输出的单词
Decoder block 最后的部分是利用 Softmax 预测下一个单词,在之前的网络层我们可以得到一个最终的输出 Z,因为 Mask 的存在,使得单词 0 的输出 Z0 只包含单词 0 的信息,如下:
Softmax 根据输出矩阵的每一行预测下一个单词:
11.5 测试过程
训练好模型, 测试的时候,比如用 ‘机器学习很有趣’当作测试样本,得到其英语翻译。
这一句经过encoder后得到输出编码信息矩阵C,送入到decoder(并不是当作decoder的直接输入):
- 然后用起始符
<bos>当作decoder的 输入,得到输出 machine - 用
<bos>+ machine 当作输入得到输出 learning - 用
<bos>+ machine + learning 当作输入得到is - 用
<bos>+ machine + learning + is 当作输入得到interesting - 用
<bos>+ machine + learning + is + interesting 当作输入得到 结束符号<eos>
我们就得到了完整的翻译 ‘machine learning is interesting’