大模型微调Fine-tuning
大模型微调Fine-tuning
大模型微调(Fine-tuning) 是指在一个已经预训练好的大语言模型(Base Model)基础上,使用特定领域的数据集进行二次训练,以调整模型的参数,使其在特定任务或特定领域表现得更好。
什么是大模型微调?
如果把预训练(Pre-training)比作一个学生在学校接受通识教育(学习各科知识,具备理解语言、逻辑推理的能力),那么微调(Fine-tuning)就是这个学生在毕业后进入职业培训(学习特定行业的专业知识,如法律、医学或特定公司的业务流程)。
为什么需要微调?
- 领域专业化:通用模型(如 GPT-4, Llama 3)虽然强大,但在极专业的领域(如中医处方、法律文书)可能表现不够精准。
- 格式与风格对齐:让模型输出符合特定格式(如 JSON、特定的回复风格)。
- 节省推理成本:通过微调较小的模型,使其在特定任务上达到甚至超过未微调大模型的表现。
主流微调技术分类
目前的技术主要分为两类:全参数微调和参数高效微调(PEFT)
1. 全参数微调 (Full Fine-tuning, FFT)
对模型的所有参数进行更新。这种方法效果最好,但对算力要求极高(显存需求是模型参数量的数倍),且容易产生“灾难性遗忘”(模型学会了新知识,却忘掉了预训练时的通用能力)。
2. 参数高效微调 (Parameter-Efficient Fine-tuning, PEFT)
这是目前工业界最主流的技术,目标是只训练极少数参数,就能达到接近全量微调的效果。
LoRA (Low-Rank Adaptation): 目前最火的技术。它不改变原模型的权重 $W_0\in \mathbb{R}^{d \times d}$,而是在旁边增加一个旁路支路,通过两个低秩矩阵 $A \in \mathbb{R}^{r \times d}$ 和 $B \in \mathbb{R}^{d \times r}$ 的乘积来模拟权重的变化,其中$r$很小。
数学表示为:
$$W = W_0 + \Delta W = W_0 + BA$$
由于旁路矩阵的参数量极小(通常不到原模型的 1%,只需$2 \times d \times r$的参数量,相比于一个完整的$r \times r$小得多),极大地降低了显存需求。训练完成后,将增量权重直接加到原始权重上,推理时无需额外计算开销。
QLoRA: 虽然LoRA通过低秩分解减少了微调参数,但是当面对超大参数模型时,大模型的原始权重和激活仍会占用大量的显存。引入了 4-bit 量化技术,将模型权重从从原始的16-bit表示,压缩到了4-bit表示,显存占用减少了约4倍,且对精度影响极小,让普通消费级显卡(如 RTX 3090/4090)也能微调百亿甚至千亿参数的大模型。
Prompt Tuning / Prefix Tuning: 不改模型参数,而是在输入层(或每一层)添加一段可学习的“连续向量”(虚拟 Token)。训练时只更新这些虚拟 Token。
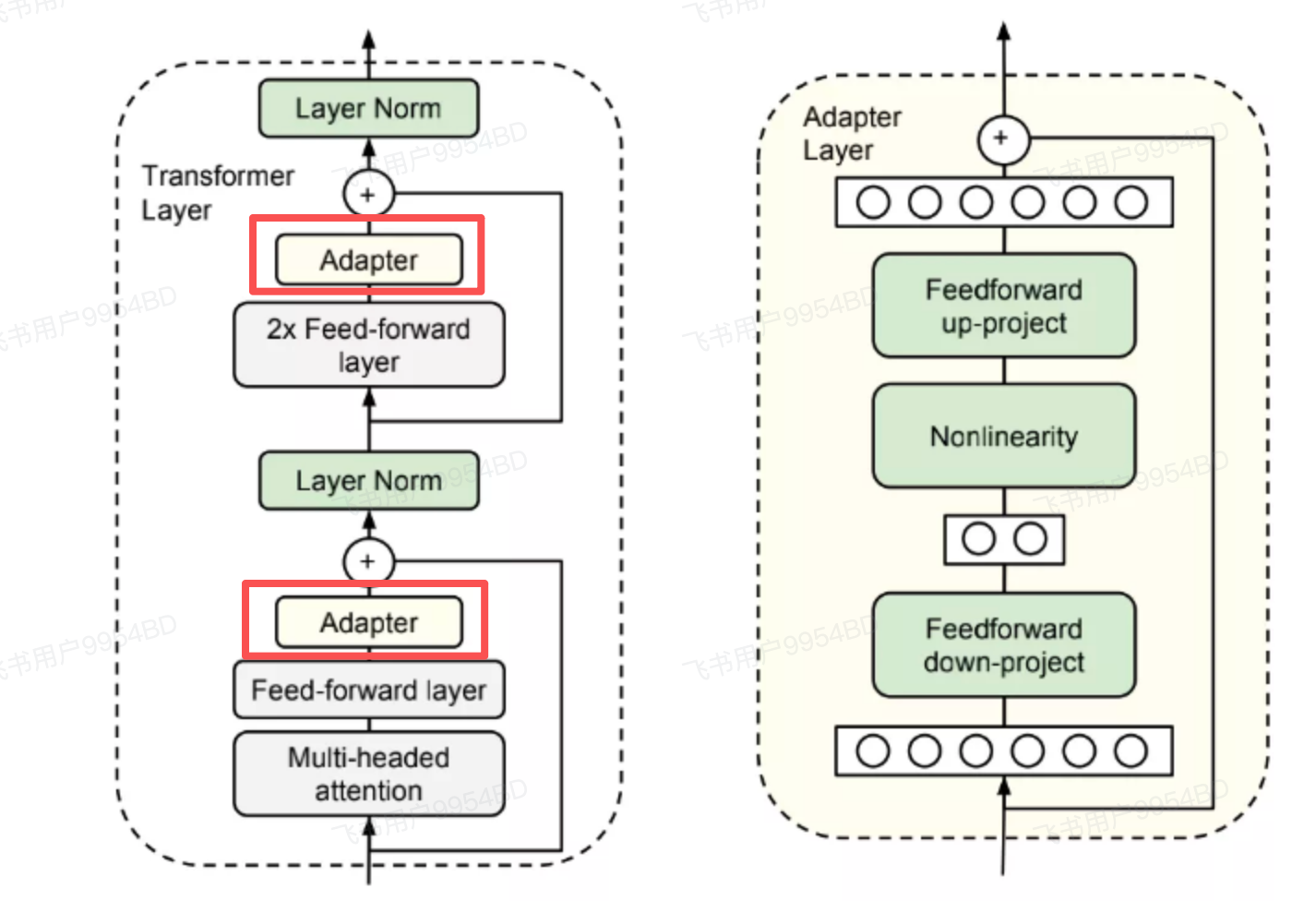
Adapter Tuning: 在模型的 Transformer 层中插入一些小型网络层(Adapter)。微调时只训练这些 Adapter。虽然减少了训练参数,但是带来了推理延迟。