近似最近邻ANN算法技术总结
近似最近邻ANN算法技术总结
参考:
近似最近邻 (Approximate Nearest Neighbor, ANN) 算法是一类用于在高维空间中快速查找与查询点最相似数据点的算法。相比精确的最近邻搜索 (KNN),ANN算法牺牲了一定的精度换取显著的速度提升,特别适用于大规模数据集。
主流ANN算法可分为以下几类:
| 类别 | 代表算法 | 特点 |
|---|---|---|
| 📊 基于量化 | IVF、PQ、IVF-PQ | 压缩存储,内存友好 |
| 🕸️ 基于图结构 | HNSW、NSW、NSG | 查询速度快,精度高 |
| #️⃣ 基于哈希 | LSH | 适合超高维,理论保证 |
| 🌲 基于树结构 | KD-Tree、Ball-Tree、 Annoy | 低维高效,实现简单 |
| 📌 其他算法 | Linear Scan | 精确搜索,小数据集 |
1. 基于量化的算法
1.1 IVF(Inverted File Index 倒排文件索引)
通过聚类将向量空间划分为多个子区域,构建倒排索引结构。查询时只需搜索最相关的几个聚类中心,大幅减少计算量。
训练阶段:使用K-Means对数据集(通常是从准备建立索引的全部向量中,随机抽取一部分)进行聚类,得到k个聚类中心:${c_1, c_2, …, c_k}$
索引阶段:将每个向量分配到最近的聚类中心,构建倒排列表(类似
Map<Cluster_ID, List<Vector_Info>>的结构)为了节省空间和提高速度,倒排列表通常不会只存原始向量,而是存储以下信息的组合:
- 向量 ID (Vector ID): 指向原始数据的唯一标识(必选)。
- 残差向量 (Residual Vector): 原始向量与聚类中心的差值(可选,用于提高精度)。
- 压缩后的数据: 比如经过 PQ(乘积量化)压缩后的编码(在高并发场景极其常用)。
查询阶段:找到距离查询向量最近的n个聚类中心,只在这些聚类的倒排列表中搜索最近邻
- 优点:实现简单、可扩展性好
- 缺点:精度依赖于聚类质量、数据分布不均匀可能导致性能下降
1.2 PQ(Product Quantization 乘积量化)
PQ (乘积量化) 将高维向量空间分解为多个低维子空间,分别进行量化,实现高效的压缩和快速距离计算
- 空间分割:将d维向量分割为m个d/m维子向量(如将一个128维的向量划分为8个16维的子向量)
- 子空间聚类:对每个子空间独立训练k(通常为256)个聚类中心(训练集同上,通常是在准备建立索引的全部向量随机抽取的一部分),这k个类中心就构成了该子空间的码本codebook,因为有m个子空间,最终会得到m个码本
- 量化编码:对于任何一个原始向量,将其切分为m个子向量,对每个子向量在对应码本中找到离他最近的那个类中心的索引(原本128维的向量,现在变成了8个索引值,每个索引值范围为 0 - 255)
- 距离计算:当用户输入一个查询向量query进行搜索时,将query也切成m段,计算每一段与对应子空间码本中那k个类中心的距离,生成一个 m * k 的距离查找表;然后遍历所有向量,对任何一个压缩后的向量,只需根据索引从查找表中取出m个距离值,加和即得到与查询向量query的近似距离(只有查表和加法,没有任何浮点数乘法)
- 优点:极高压缩率、查询速度快
- 缺点:精度损失较大、训练时间较长
1.3 IVF-PQ
单纯使用 PQ 时,虽然每个向量都被压缩得很小,但检索时依然需要将 Query 与库中所有向量进行对比(全量扫描)。当数据量达到亿级时,即便只是查表加法,计算量依然巨大。
IVF-PQ 的核心思路是: 先用 IVF 把搜索范围从“全世界”缩小到“几个街区”,再用 PQ 在这几个街区里进行快速特征匹配。
粗聚类:首先对所有原始向量进行一次大规模的K-Means聚类,得到k个聚类中心,将每个向量根据距离分配到离它最近的类的倒排列表里
残差量化:不直接对原始向量做PQ,而是对它们的残差:$r = x - c_i$ 做PQ,其中$c_i$为原始向量$x$所属类中心
为什么量化残差?
因为属于同一个类中心的向量通常比较接近,它们的残差值域更小、分布更集中。对残差进行 PQ 量化,误差会比直接量化原始向量小得多,从而提高检索精度。
查询检索:当用户输入一个查询向量query进行搜索时,首先计算query与k个类中心的距离,选出最近的n个类中心对应的倒排列表;计算query与这n个类中心的残差,在这n个倒排列表中,利用PQ快速算出query与倒排列表中各个向量的近似距离,汇总这n个倒排列表的结果,得到topK
2. 基于图结构的算法
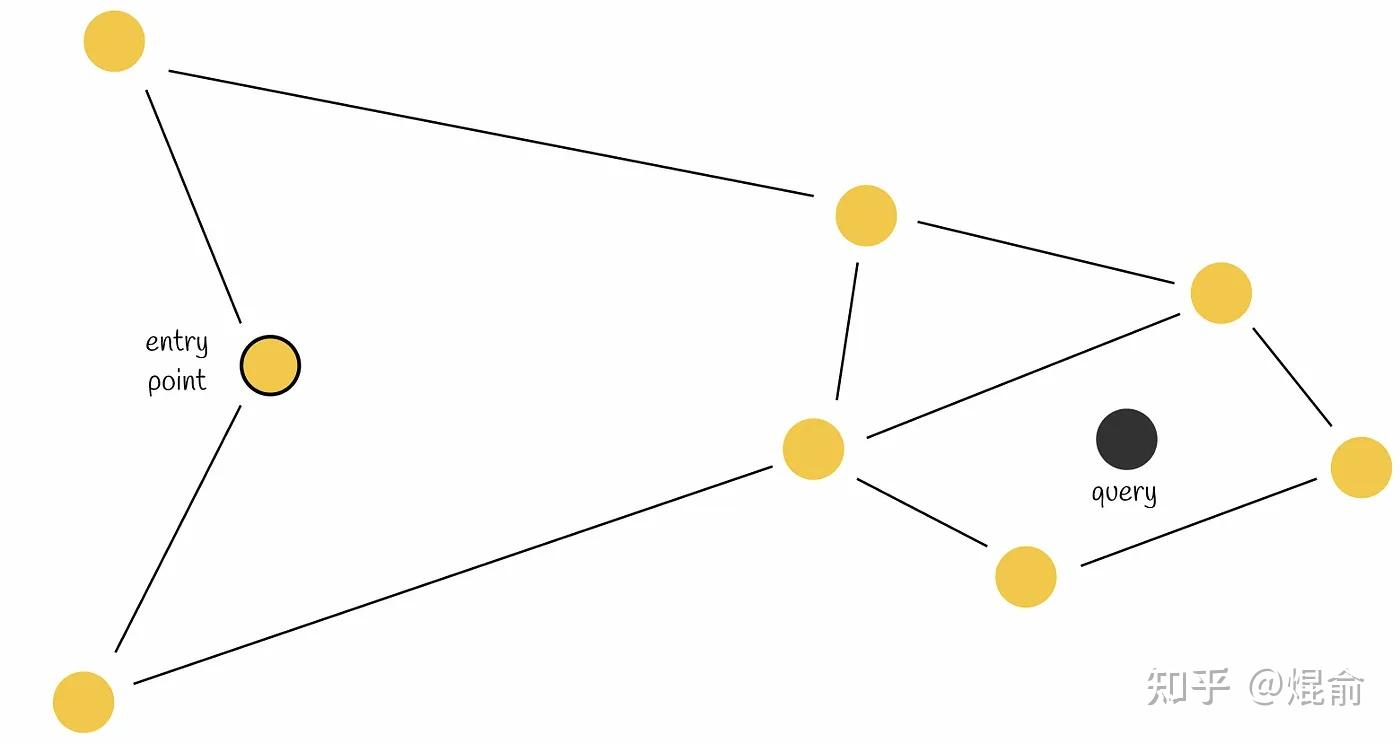
2.1 NSW(Navigable Small World)
在一个图中,大部分节点并不直接相连,但通过少数几次跳转就可以到达目标节点。NSW 模拟了这种“六度分隔”理论。
构图过程:
向图中逐个插入点,对于新插入的点,通过贪心搜索找到图中距离它最近的m个点,并与它们建立边
贪心搜索的执行步骤
假设我们有一个查询向量 $q$,图中已经存在一些点和边。贪心搜索的过程如下:
- 确定起点:从图中的某一个起始点 $v_{start}$ 开始(在 NSW 中通常是随机选一个或固定一个)。
- 查看邻居:计算当前节点 $v$ 的所有直接邻居到查询向量 $q$ 的距离。
- 做出选择(贪心点):
- 在所有邻居中,找到距离 $q$ 最近的那个节点 $v_{next}$。
- 判断位移:如果 $dist(v_{next}, q) < dist(v, q)$(即邻居比当前点更靠近目标),则跳到 $v_{next}$,将其作为新的当前节点。
- 循环与终止:重复步骤 2 和 3。
- 停止条件:当你发现当前节点的所有邻居都比当前节点离 $q$ 更远时,搜索停止。此时的当前节点就是该算法找到的局部最近邻。
早期插入的点:由于当时图中点很少,它们连接的边往往跨度很大,起到“高速公路”作用
后期插入的点:由于图中点变多,它们连接的边更趋向于局部邻居(短距离边)
搜索过程:
- 从一个随机点(或固定起始点)开始。
- 计算当前节点的所有邻居与查询向量 $q$ 的距离。
- 移动到距离 $q$ 最近的邻居节点。
- 重复上述过程,直到当前节点比所有邻居都更接近 $q$,搜索停止
缺点:容易陷入局部最优,可以通过使用多个入口节点来提高搜索点准确性
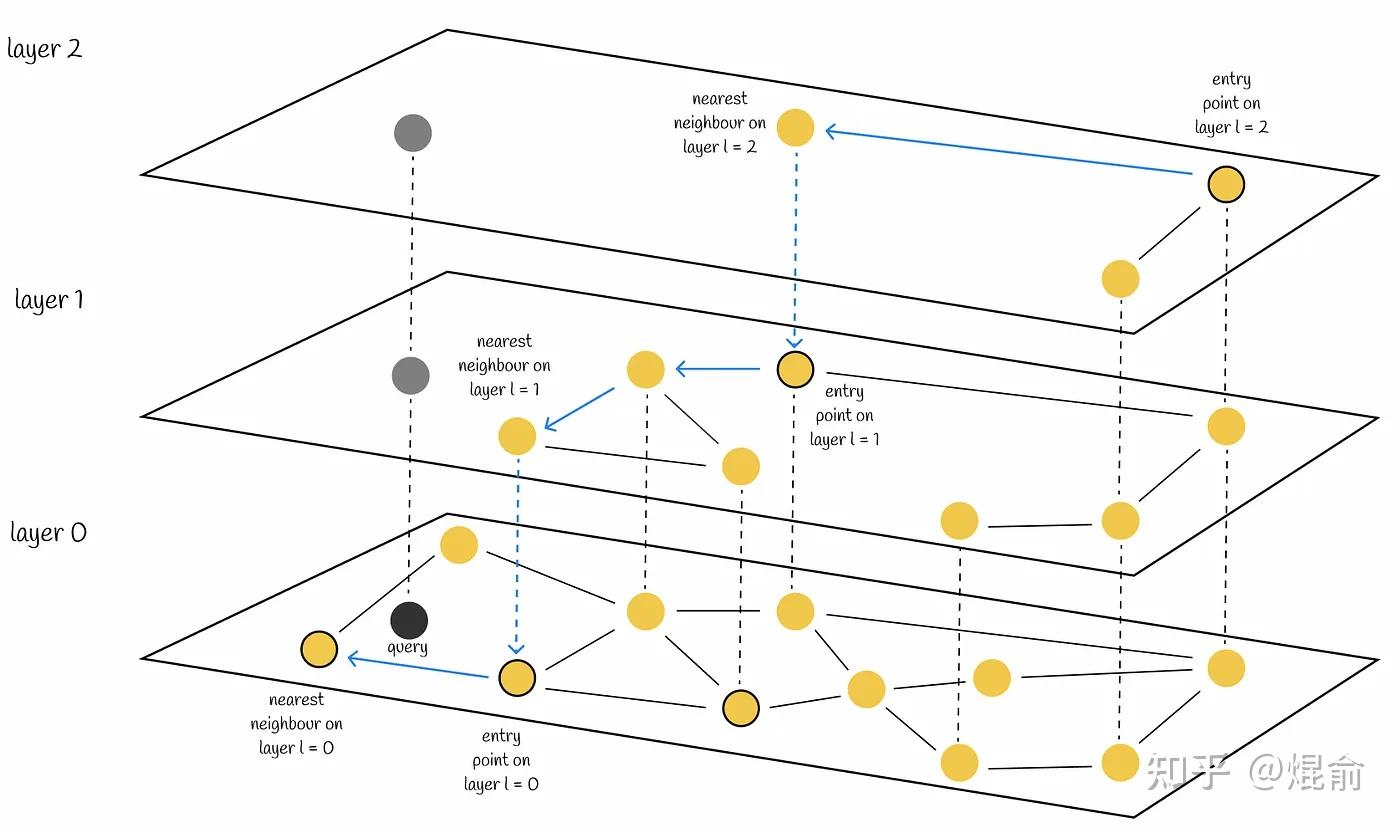
2.2 HNSW(Hierarchical Navigable Small World)
HNSW是当前性能最优的ANN算法之一,通过构建多层可导航小世界图实现高效搜索。
HNSW基于跳表和NSW,构建了一个多层图,顶层的图连接少,底层的连接稠密,上层用于快速全局定位,下层用于精细搜索。每层通过贪心策略逐步逼近目标
与NSW类似, HNSW的搜索质量可以通过使用多个入口点来提高
3. 基于哈希的算法
3.1 LSH(Locality Sensitive Hashing)
LSH通过特殊的哈希函数,将相似的向量映射到相同的哈希桶,实现快速近似搜索。与传统哈希(如 MD5、SHA-1)致力于“避免碰撞”不同,LSH 的核心思想是“制造碰撞”——即让空间中距离较近的点,经哈希映射后有更高的概率落入同一个桶中
局部敏感性定义:一个哈希函数族 $\mathcal{H}$ 被称为 $(d_1, d_2, p_1, p_2)$ - 敏感的,需要满足:
- 如果两个点 $x, y$ 的距离 $d(x, y) \le d_1$,则它们哈希值相同的概率 $P[h(x) = h(y)] \ge p_1$。
- 如果两个点 $x, y$ 的距离 $d(x, y) \ge d_2$,则它们哈希值相同的概率 $P[h(x) = h(y)] \le p_2$。
- 其中满足 $d_1 < d_2$ 且 $p_1 > p_2$。
这意味着:距离近的点更容易“撞”在一起,距离远的点很难“撞”在一起
索引阶段:
- 特征提取:将原始数据转换为高维向量
- 哈希映射:选择合适的 LSH 函数族。为了提高准确率,通常不会只用一个哈希函数,而是使用多组哈希函数
- 构建索引:将所有数据根据哈希值存入不同的“桶”(Buckets)中
查询阶段:
- 查询转换:对查询向量 $q$ 执行同样的哈希映射。
- 候选集提取:找到 $q$ 落入的桶,取出该桶(以及相邻桶)中的所有数据点作为候选集。
- 精确重排:在候选集中进行精细的距离计算(如欧氏距离或余弦距离),返回最终的 Top-K 结果
性能优化:为了在高召回率(Recall)和高精度(Precision)之间取得平衡,LSH 通常采用多层级构造:
AND 构造(增加行数 $k$):
只有当 $k$ 个哈希函数的结果全相等时,才认为两个点可能相似。这会降低点落入桶的概率,从而减少错误匹配(提高精度),但可能会漏掉一些点。
OR 构造(增加表数 $L$,一张表可以理解为多个哈希桶的集合):
建立 $L$ 个独立的哈希表。只要在任意一张表中点 $x, y$ 撞桶了,就将其加入候选集。这会提高点被找到的概率(提高召回率)。
4. 基于树结构的算法
4.1 KD-Tree(K-Dimensional Tree)
4.2 Annoy(Approximate Nearest Neighbors Oh Yeah)
5. 其他算法
5.1 线性扫描(Brute Force)
计算查询向量与所有数据点的距离,返回top-k最近邻