Redis字符串的embstr编码和raw编码之间的界限为什么是44字节
Redis字符串的embstr编码和raw编码之间的界限为什么是44字节
核心结论:44 字节是为了让整个 RedisObject 对象(包含 SDS Header 和字符串内容)刚好填满 64 字节的内存块
1. Redis字符串编码类型
Redis 字符串内部内部编码有三种:
int:存储 8 个字节的长整型embstr:代表embstr格式的 SDS,存储小于 44 个字节的字符串(3.2 版本之前是 39 个字节),只分配一次内存空间(因为RedisObject和 SDS 是连续的,但它是只读的,任何修改都会导致它升级为raw,因为原地修改embstr成本很高)raw:存储大于 44 个字节的字符串(3.2 版本之前是 39 个字节),需要分配两次内存空间(分别为RedisObject和 SDS 分配空间)
2. embstr结构
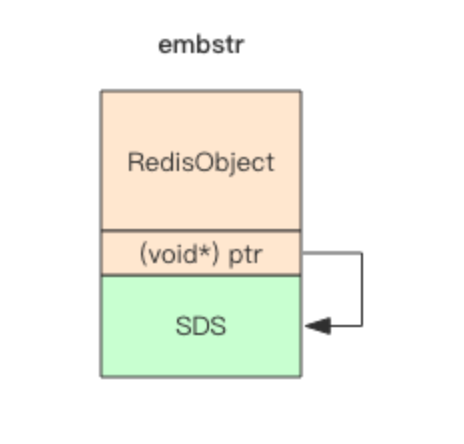
embstr分配的是连续的一块内存,包含redisObjec和sds,redisObject占用了16个字节
2.1 Redis3.2之前的embstr
1 | |
当存储39字节时,embstr大小为:16(redisObject) + 4(len) + 4(free) + 39(buf) + 1(\0) = 64字节
也就是说只要是存储的内容小于39个字节的,分配的空间都是64个字节。超过64个字节就为raw
2.2 Redis3.2之后的embstr
sds使用了uint8_t代替uint,占用的内存空间更小了
1 | |
当存储44字节时,embstr大小为:16(redisObject) + 1(len) + 1(alloc) + 1(flags) + 44(buf) + 1(\0) = 64字节
同理也是超过64字节就为raw
2.3 特殊情况:sdshdr5
由于 sdshdr5 的结构和 sdshdr8/16/32/64 不同,它不直接用来做embstr
Redis 字符串的物理表现总结为三级:
- 极小静态(sdshdr5):主要在内存极度受限或冷数据加载时由系统内部使用(通常 < 32 字节)
- 小动态(embstr + sdshdr8):0 到 44 字节。这是最常见的形态,连续内存,一次分配,性能最高
- 大动态(raw + sdshdr8/16/32/64):大于 44 字节。两次分配,内存不连续,适合存储大数据或频繁修改的数据
3. 为什么是64字节?
在 Linux 中,主流的内存分配器(如 jemalloc)是以 $2^n$ 次方来划分内存池的。而 CPU 的 Cache Line(缓存行) 大小通常也是 64 字节
- 如果一个对象超过了 64 字节,它可能就需要跨缓存行存储,或者被分配到 128 字节的内存块中,这会造成内存碎片和性能下降。
- 因此,Redis 希望尽可能将小的字符串控制在 64 字节以内。
Redis字符串的embstr编码和raw编码之间的界限为什么是44字节
http://example.com/2026/02/05/Redis字符串的embstr编码和raw编码之间的界限为什么是44字节/