Caffeine常见面试题
Caffeine常见面试题
一、Caffeine 基础相关
Caffeine 的原理、特性是什么?
原理
采用 W-TinyLFU 淘汰算法,底层通过分段锁减少并发竞争,结合惰性删除、异步加载等机制实现高性能
特性
性能高:基于 W-TinyLFU 淘汰算法,命中率 / 吞吐量比传统的 LRU、LFU 算法要好
缓存策略比较丰富:支持基于大小、时间、引用类型的过期 / 淘汰策略;
加载比较灵活:支持手动加载、自动加载、异步加载
高并发性能:无锁设计,分段锁机制
事件监听:支持缓存淘汰、过期、移除的事件监听,便于问题排查
兼容性:API 几乎和 Guava Cache 一致,迁移成本低
Caffeine 缓存主要存储什么数据?
热点数据(秒杀商品库存)、高频访问 + 低变更数据(商品基础信息)
Caffeine 缓存的数据具体是怎么添加的?
手动添加(cache.put,直接添加缓存项), 同步加载(cache.get,通过加载器自动加载,未命中时执行加载逻辑),异步加载(也可以根据自己的实际业务作出回答)
二、Caffeine 与其他组件的区别
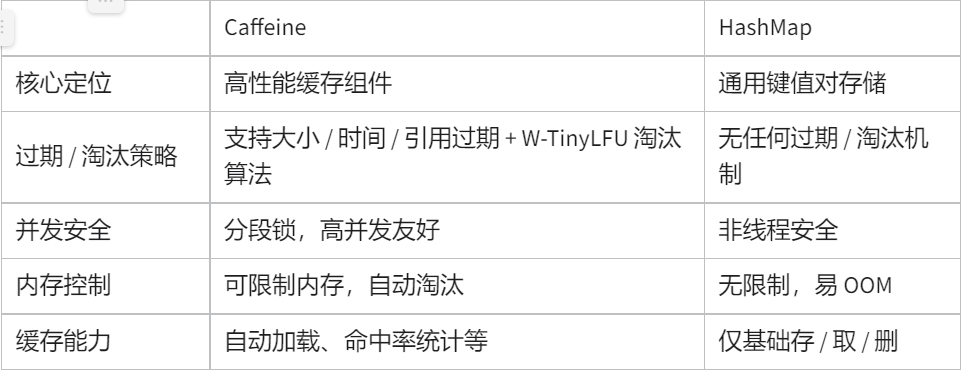
Caffeine 与 HashMap 的区别?
Caffeine 与 Guava Cache 的区别?
区别性能:Caffeine 命中率高,吞吐量大;
并发:Caffeine 支持异步加载,Guava 仅同步加载;( Caffeine 并不像 Guava Cache 那样在读写操作时立即加锁,而是使用 RingBuffer(类似 RingBuffer 的环形队列)将写操作、淘汰、更新等操作记录下来,然后异步、批量地执行。)
算法:Caffeine 用 W-TinyLFU,Guava 用 LRU;
功能:Caffeine 支持异步刷新,Guava 同步刷新易阻塞。
兼容性好:API 兼容 Guava,迁移成本低解决的问题
Caffeine 解决了 Guava 的哪些问题?
Guava 的 LRU 易被偶发冷数据冲掉热点,W-TinyLFU 兼顾热点保留与冷数据淘汰;
Guava 同步加载导致高并发下线程阻塞,Caffeine 异步加载避免此问题;
Guava 无原生异步加载,需手动封装,Caffeine 内置
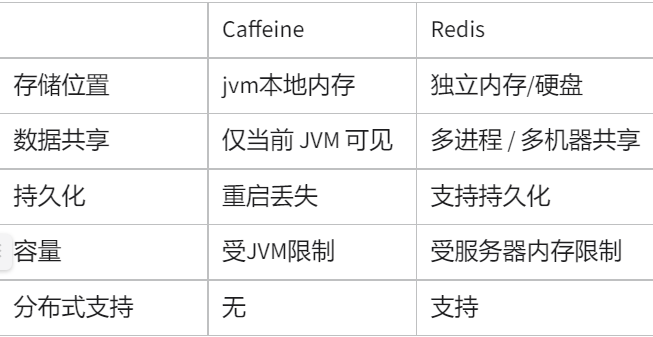
Caffeine 与 Redis 缓存的区别?
三、Caffeine 核心机制
Caffeine 为什么比 Guava 快?
算法:W-TinyLFU 算法时间复杂度更低,命中率更高
并发:Guava通过类似ConcurrentHashMap的分段锁减少竞争;而Caffeine读操作几乎无锁,写入、删除操作交给独立的线程池异步执行
异步支持:内置异步加载,避免同步阻塞
惰性操作:过期数据惰性清理,避免后台线程开销
Caffeine 本地缓存的失效(淘汰)算法是什么?
W-TinyLFU解决传统 LRU/LFU 缺陷
LRU:缓存 “突发流量的临时数据”,挤占常用数据
LFU:缓存 “历史高频但当前无用” 的数据;
- 对新数据不友好计数最小草图(Count-Min Sketch)用 “近似统计” 替代 “精确统计”解决 LFU 的 “频率统计内存开销大” 问题;
- 频率衰减解决 LFU “历史高频数据占坑” 问题
- 单独开辟一个 “窗口缓存”,专门接纳新数据,给新数据一个 “观察期”,避免刚进来就被淘汰,解决 LFU 的 “新数据歧视” 问题
多线程请求数据时,Caffeine 缓存未命中的内部处理逻辑是什么?(例:多线程同时请求同一数据)
核心是 请求合并(避免缓存击穿)第一个线程请求未命中时,标记 key 为 “加载中”,执行加载逻辑;
后续线程请求同一 key 时,不重复加载,等待第一个线程完成;
加载完成后,结果放入缓存,所有等待线程获取结果;
加载异常时,所有线程抛出异常,缓存不存储异常结果。
给 Caffeine 预留固定内存(如 128M),并发量高导致数据存不下时如何处理?
临时调整缓存配置(缩短过期时间+提高淘汰优先级+临时扩容)通过配置中心关闭非核心场景的 Caffeine 缓存,非核心热点 key 直接走 Redis若 JVM 堆内存剩余较多,临时提高 Caffeine 内存上限(比如,128 ——> 256)
四、Caffeine 的优缺点与选型
用 Caffeine 缓存有什么缺点?
仅支持本地缓存,无法解决分布式场景下的数据共享问题
JVM 重启丢失,可能引发数据库瞬时压力仅能存热点数据,无法存储大规模数据一致性难保证,更新需手动失效,易遗漏
五、缓存一致性问题
Redis 和 Caffeine 的缓存一致性如何保证?
最终一致性写流程:更新数据库 → 更新 Redis → 删 Caffeine;
读流程:查 Caffeine → 查 Redis → 查数据库(查库后更新 Redis 和 Caffeine);
兜底:Redis 设置短过期(30 分钟),Canal 监听 binlog 异步刷新缓存,MQ 广播缓存失效事件(集群场景)
本地缓存的一致性如何保证?
采用双写策略:先更新数据库,再更新 Redis 和 Caffeine
通过消息队列或发布-订阅机制同步更新设置较短的过期时间,保证数据最终一致性
本地缓存失败了怎么办?
降级策略:本地缓存失败时直接读Redis
监控告警:缓存命中率低于阈值时告警
六、多级缓存架构
Redis 缓存和本地缓存(Caffeine/Guava)如何取舍?
选 Caffeine:访问频率高、数据量小、单节点使用的热点数据;
选 Redis:数据需共享、容量大、需持久化 / 分布式支持的场景
采用 Redis+Caffeine 两级缓存是出于什么考虑?
性能:本地缓存减少网络延迟稳定性:即使 Redis 故障,Caffeine 仍可提供服务
数据库保护:大幅减少数据库查询压力
缓存压力:分流热点请求,降低 Redis 负载
多级缓存主要解决了什么问题?
- 性能瓶颈:应对突发流量,保护下游存储
- 数据库的读压力过大
- 网络延迟导致的响应时间长
- 单级故障不影响全局
七、缓存命中率问题
若 Caffeine 本地缓存命中率不高,会产生什么问题?
如何解决?
问题性能下降:请求穿透到 Redis / 数据库,接口响应变慢资源浪费:占用 JVM 内存但无缓存效果
解决
- 优化配置:调整过期时间,增加缓存大小
- 缓存预热:系统启动时加载热点数据到缓存
- 监控与告警:实时监控缓存命中率,设置告警阈值