知识获取分享平台
知识获取与分享平台
知识社区App,支持发布知识、点赞/收藏、关注取关、首页Feed展示、AI生成摘要等等。项目各模块进行了充分详细的设计以满足高并发和高可用需求
一、认证系统
开发JWT双令牌认证系统,采用RS256签名 + Redis刷新令牌白名单,实现15分钟访问令牌 + 7天刷新令牌的安全会话管理,支持即时令牌撤销,兼顾高安全和高性能。
1.1 有状态身份验证和无状态身份验证
- 有状态身份验证:服务器端保存用户的会话状态信息,当用户访问时会携带上会话标识(如sessionid),服务器查找是否有这个会话来判断是否放行
- 无状态身份验证:服务器端不保存用户的会话状态信息,用户登录时,服务器使用私钥加密生成一个token返回给客户端,用户访问时带上这个token,若能用私钥解密,则允许访问。
1.2 什么是双令牌机制
服务器返回两个token给客户端,一个access token(AT)用于访问,一个refresh token(RT)用于刷新access token。
| Access Token | Refresh Token | |
|---|---|---|
| 持续时间 | 短,15min | 长,7d |
| 用途 | 用于客户端访问 | 用于刷新AT |
| 是否无状态 | 是 | 否,需要将RT存储在Redis中,通过查询Redis中是否有对应RT来判断RT是否过期,这样的好处是能够方便强制踢人下线,保障了安全管控能力 |
所以本项目实现的是一个半无状态的双token机制,兼顾高安全与高性能。
1.3 token保存在什么地方
JWT Token 存放在 HTTP 请求头的Authorization 字段中,格式为:
1 | |
客户端在登录成功后,会将服务端返回的 token 保存在:
localStorage / sessionStorage (本项目中使用此种保存方法)
localStorage 是一种浏览器提供的客户端存储机制,允许开发者在用户的浏览器中以键值对的形式存储数据。与 sessionStorage 不同,localStorage 中的数据可以长期保留,直到手动删除。
Cookie (如果使用 HttpOnly Cookie)
内存变量 (如 Redux/Vuex 状态)
每次发送请求时,客户端需要手动在请求头中加上这个 token。流程如下:
1 | |
1.4 token过期验证流程
场景1:token正常
1 | |
场景2:token快过期(还有几秒)
1 | |
场景3:token已过期(前端没刷新成功)
1 | |
1.5 token使用什么加密算法?token里包含什么信息?
本项目中的Jwt采用RSA-256非对称加密算法,原理如下:
| 密钥类型 | 作用 | 谁持有 |
|---|---|---|
| 私钥 (private.pem) | 签名 Token(加密) 生成:header.payload.signature |
只有后端服务器持有 |
| 公钥 (public.pem) | 验证 Token(解密) 检查:signature 是否匹配 header + payload |
可以公开,任何人都能验证 |
一个完整的Jwt长这样:
1 | |
Header(头部) - 算法信息
1 | |
Payload(负载) - 实际数据
1 | |
Signature(签名) - 防篡改
1 | |
1.6 Jwt验证完整流程
1 | |
1.7 双令牌相比于单令牌有什么优势
- 降低 Token 泄露后的风险:在单 Token 机制下,Token 通常有效期较长(如 7 天),一旦被黑客截获,黑客在 7 天内可以随意访问用户数据。在双 Token 机制下,AT有效期极短,即使被窃取,攻击者也只能在极短时间内进行攻击;同时,由于RT通常只在刷新时才发送给服务器,泄露风险远低于频繁使用的AT
- 兼顾“无状态”与“强制下线”能力:单 Token 最大的缺点就是一旦签发无法撤回。在双 Token 机制下,如果发现异常登录或用户修改密码,服务器可以作废 RT。这样,当用户的短效 AT 到期去刷新时,会因为 RT 失效而被强制踢下线。这在保持大部分请求“无状态”的同时,保留了对会话的控制权
- 提升用户体验(无感刷新):单 Token 机制如果为了安全设置短有效期(如 30 分钟),用户每隔半小时就要重新登录一次,体验非常糟糕。在双 Token 机制下,AT过期后会自动携带RT向后端申请新的AT,用户在几天的使用过程中,完全感知不到 Token 的更替,除非 RT 也过期了才需要重新输入账号密码。
二、计数系统
计数系统:笔记维度(点赞收藏)与用户维度(关注取关) 以 Redis 作为底层存储系统,采用定制化 Redis SDS 二进制紧凑计数,使用 Lua 脚本进行原子更新,并实现了采样一致性校验与自愈重建。
2.1 为什么要单独把计数模块抽出来,有什么好处?
计数类数据(浏览量、点赞数、收藏数、关注数、粉丝数等)有几个典型特征:
- 读写极高频:一个热门用户/热门作品,计数每秒都在变。
- 更新粒度小且随机:每次只改一个数,还可能集中打在少数热点 Key 上。
- 对“绝对强一致”要求没那么死:10001 和 9999 对用户来说差别不大,比起“页面加载很慢/操作失败”,用户更在乎“流畅”。
如果计数都落在 MySQL:
- 热点行会频繁 UPDATE,行锁、redo log 压力巨大,很容易撑爆。
- 想做分库分表,计数又和业务数据纠缠在一起,拆分困难。
- 任意一个计数维度新增或变更,都要改表结构,DDL 成本很高。
所以:把计数抽出成一个独立的“计数服务 + Redis 存储”,是更合理的架构拆分。
2.2 选择Redis作为底层存储系统可靠吗?
- 可以使用 RDB + AOF 混合持久化的方式,将数据持久化到本地;AOF开启策略everysec,理论上最多丢失1s的数据
- 如果担心redis宕机,可以使用 多副本 + 主从 的模式,确保一台redis服务器宕机了,另一台能立马顶上
- 对于 RDB + AOF 可能丢失的1s的数据,也可能与数据库事实表出现不一致,可以通过执行定时对账任务,和事实表进行对账来修正(本项目的:采样一致性校验与自愈重建)
- 在极端情况下,比如硬盘损坏,也可以通过和事实表定期对账,来找回丢失的数据 / 修正错误的数据
2.3 为什么采用自定义的二进制Redis SDS来计数,讲一下存储计数的实现细节
对于作品维度,有点赞数、收藏数;对于用户维度,有关注数、粉丝数、作品数、获赞数、获收藏数,乍一看来,好像是使用Hash来存储更加合适:
1 | |
但是随着业务规模上涨,用户数、作品数增加,如果每个用户/作品都在Redis里维护一个这样的Hash结构,先不谈数据多少,元数据的字段名就占了很多重复的空间,浪费内存
我们设计的紧凑计数:
1 | |
没有字段名,只存值,节省空间;寻找对应的数据只需:“起始地址 + 类型偏移”即可。我们为每一个key分配了20字节的value,每个value分成5段,每段4字节存储对应数值。
2.4 采样一致性校验和自愈重建是怎么做的?
每隔300s,在查询Redis SDS中数量的时候,去对比和数据库中事实表的实际值,如果不一致,就触发重建(用户关系每隔300s检查是否一致;而点赞系统每次获取数量都判断最终计数结构是否完整,只有结构不完整才会重建)。
采样 = 不是每次请求都校验,而是按一定频率抽样检查:
- 限流机制:使用 setIfAbsent (相当于 SETNX) 实现分布式锁,过期时间300s,保证300s内只有一个线程能够校验并重建
- 如果 300 秒内第一次访问:key 不存在,设置成功 → doCheck = true,执行校验
- 如果 300 秒内已校验过:key 已存在 → doCheck = false,跳过校验
- 校验内容:对比 Redis SDS 中的关注/粉丝数与数据库实际值
- 修复机制:发现不一致时,触发 rebuildAllCounters() 全量重建
为什么需要采样校验?
性能考虑:每次查询都去数据库校验会严重影响性能
最终一致性:通过定期采样保证缓存与数据库的最终一致性
自动修复:自动检测并修复可能出现的数据不一致问题
三、用户关系系统
实现关注功能,采用一主多从+事件驱动模型。粉丝表,计数系统,列表缓存都作为关注表的伪从。关注事件发生时,在同一事务中插入关注表和 Outbox 表,使用 Canal 订阅 Outbox 表的 binlog,并将变更事件发布到 Kafka 异步更新其他数据源。
3.1 用户关系系统是怎么实现的?什么是“一主多从+事件驱动”?
当用户A关注用户B时,以下多张表会发生更新:
- 关注表(MySQL)需要新增:A -> B
- 粉丝表(MySQL)需要新增:B -> A
- A关注数 + 1,B粉丝数 + 1(Redis)
- A关注列表缓存、B粉丝列表缓存更新(Redis)
这么多操作,如果有一个发生错误,就会导致数据不一致的情况。为了解决一致性的问题,可能会想到,使用分布式事务,将这多个任务都放在一个事务里,就能解决多张表之间的一致性问题。
但是,随之而来的新问题,多个任务放在同一个事务里,会导致性能变差,特别是对于热点用户,后续如果有新的任务需要添加,性能只会越来越差。而且,多个任务放在同一个事务里,如果有一个组件挂了,整体就会一起挂,耦合性变得非常高。
而在我们的用户关系系统里,当用户A关注了用户B后,用户B的粉丝表、用户A的关注数、用户B的粉丝数等这些都不需要非常强的一致性,只需要保证最终一致即可。于是我们将关注表作为主表,其他作为从表,我们只关注主表是否成功,主表成功就算业务成功,下游任务可以容忍慢一点,甚至短暂挂掉,后续只要通过重建措施来保证最终一致性即可。
| 表 | 性质 | 是否必须一致 |
|---|---|---|
| following(关注表) | 唯一真相 | 必须准确 |
| follower(粉丝表) | 粉丝投影表 | 可延时,但必须可修正 |
| 计数(Redis SDS) | 聚合投影 | 可延时,可修正 |
| 列表缓存(ZSet / Caffeine) | 性能投影 | 可延时,可修正 |
我们通过一个新的表:outbox表,来记录following主表的事件,一个事务里只需要完成following表 + outbox表的更新即可。然后通过Canal去订阅outbox表的binlog,再通过Kafka去异步消费outbox表中的事件以更新下游的follower表、Redis计数、缓存(kafka带上userId作为key,保证一个用户的所有事件都进入同一个分区,确保顺序消费)。这就是“一主多从 + 事件驱动”。
3.2 这种模式有什么好处?
- 高可扩展性:在没有使用outbox表之前,如果想在下游添加新的任务,需要放在一个事务里,拖垮性能。使用outbox表之后,新来的任务只需要新增一个消费者去订阅Kafka事件,就能够无限扩展下游服务。
- 高可用性:在没有outbox表时,如果不把所有任务放在一个事务里,那么follower表只要有一次失败,那就永远不一致;Redis计数也是同理。添加outbox + canal + kafka之后:
- kafka具有重试机制,同时消息会持久化到本地,保证了不会丢消息
- 下游任务可以通过outbox表,进行重建
- 由于我们保证了following是强一致的,即使下游Redis计数任务有不一致,也可以通过每日自动比对following聚合值与Redis计数是否一致,并自动修复,来保证计数任务的一致性
3.3 讲一下Canal的原理
canal的工作原理就是把自己伪装成MySQL slave,模拟MySQL slave的交互协议向MySQL Mater发送 dump协议,MySQL mater收到canal发送过来的dump请求,开始推送bin log给canal,然后canal解析bin log,再发送到存储目的地,比如MySQL,Kafka,Elastic Search等等。
3.4 讲一下Outbox设计模式
Outbox模式主要用于解决在微服务架构中,数据库更新与消息发送之间可能出现的不一致性问题。其基本思想是:
- 创建Outbox表:在数据库中增加一个专用的Outbox表,用于存储待发送的事件或消息。
- 原子性操作:在同一个数据库事务中,先更新业务相关的数据库表(如订单表),然后将事件记录插入到Outbox表中。这样可以确保这两个操作要么同时成功,要么同时失败,保证数据的一致性。
- 异步发送:一个独立的进程(如消息中继或调度器)定期查询Outbox表(本项目中的Canal),将待发送的消息发布到外部消息代理(如Kafka、RabbitMQ等)。在消息成功发送后,更新Outbox表中对应消息的状态
3.5 用户关系系统中如何保障消息的幂等性?
- Canal每次拉取outbox表中一批未确认的消息,只有消息解析成功并被成功发送到Kafka,才会ack这一批消息,保证了Canal中的幂等
- Kafka也采用手动提交offset的方式,只有消息都被成功消费了,才会提交
- 而对于消费者中每一个用户关注事件,通过Redis分布式锁(10min的setnx),来实现一个用户关注事件只被消费一次,保证了幂等性
3.6 用户关系系统如何实现重建?
采样校验:查询关注数/粉丝数等Redis计数时,使用 Redis 锁限流,每用户 300s 触发一次,去和数据库中的事实表做比较,不一致则重建。
3.7 Outbox表的结构?Outbox表binlog中哪些信息可以被Canal监控并发送消息?
Outbox表结构如下:
1 | |
其中payload字段为如下Json:
1 | |
Canal通过监控outbox表中,事件类型为INSERT或UPDATE的数据行,并将payload字段发送给kafka,这个字段包含了完整的业务信息。最终发送到kafka的消息结构:
1 | |
四、点赞系统
采用异步写+写聚合的形式应对高并发写场景。采用分片位图的结构高效实现幂等和判重。读取遇到异常或缺失时,基于位图做按需重建,保证最终一致。
4.1 点赞系统是怎么设计的?
点赞系统存在如下“矛盾”:
- 一方面,用户操作后需要“即时生效”的交互反馈(如点击点赞后立即显示“已点赞”状态),这要求用户维度的状态具备强一致性;
- 另一方面,实体的总计数(如点赞数)对实时性要求较低,允许秒级最终一致。
于是,点赞系统也效仿用户关系系统,采用“一主多从 + 事件驱动”的设计。记录用户是否点赞/收藏的位图bitmap(key为作品id)作为主表,需要强一致性;而作品点赞数、收藏数等这些不需要非常精确的计数作为从表,通过消费事件来同步(异步写),保证最终一致性。只要确保主表bitmap正确,即使计数有不一致,也可以通过正确的bitmap进行重建。
4.2 什么是“写聚合”
如果每发生一次点赞操作,更新位图bitmap的同时,直接去更新最终计数存储(Redis SDS),会导致形成高频次、细粒度的写请求,特别是对于热点帖子,它们的计数键会成为热点行,集中占用存储节点的资源。单条行为的计数更新数据量极小,但高频请求会占用大量网络带宽;同时,存储层需要处理海量零散写请求,硬件资源利用率低,导致成本浪费。
所以需要一个中间层,去将 同一实体(同一帖子)、同一指标(点赞/收藏)在同一时间窗口内的多次增量更新聚合为一次批量更新,减少最终存储层的写次数,这就是“写聚合”。具体通过Redis的一个Hash结构实现,架构图如下:
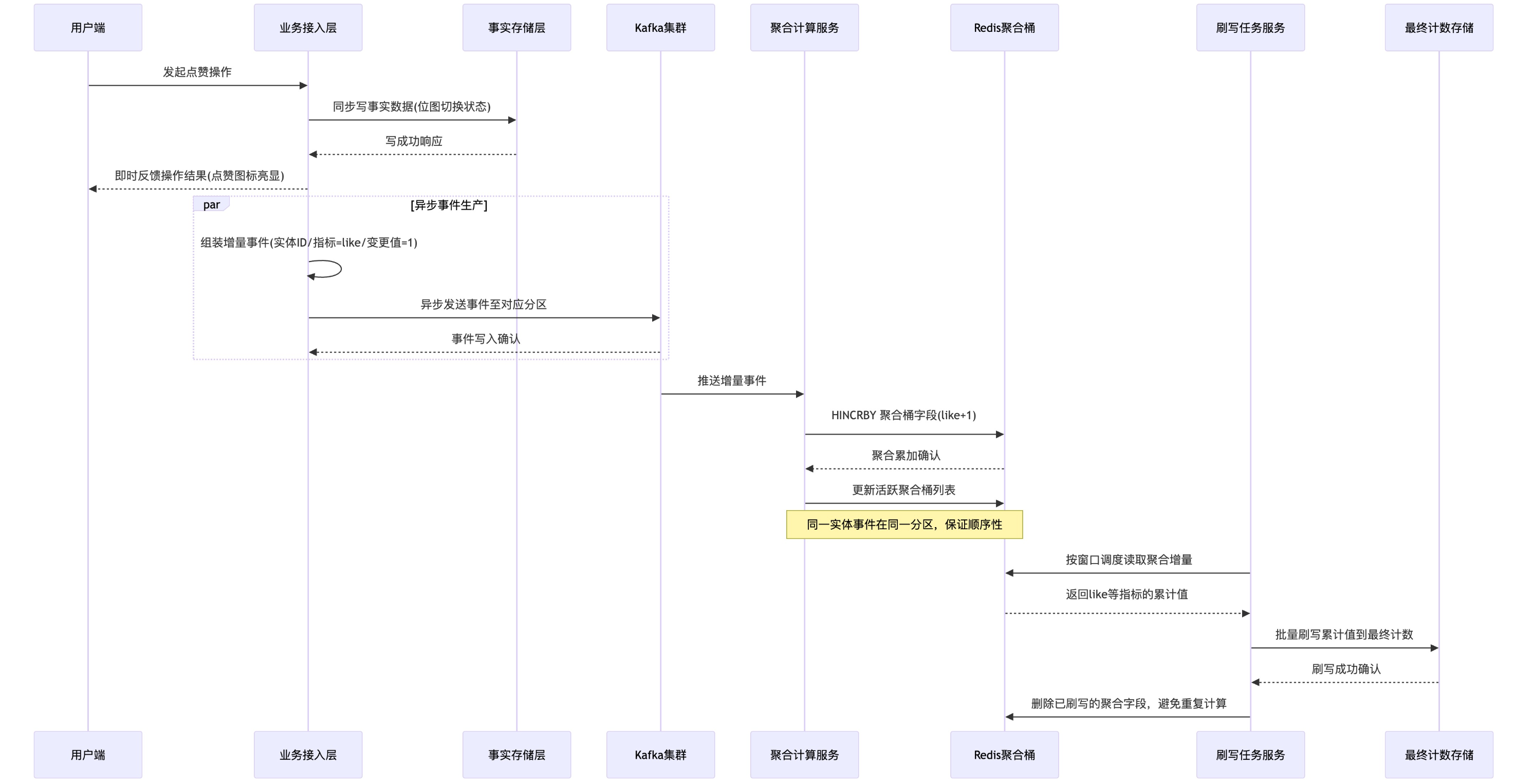
用户发起点赞操作,去更新位图(这一步需要强一致),然后即时返回点赞结果
位图更新成功后,产出事件供kafka去消费(更新点赞数、触发点赞数缓存失效),以作品id为key,保证同一个作品的所有事件都进入同一个分区,保证顺序消费
kafka消费事件时,并不是直接写入最终存储层的自定义SDS,而是先写入一个Redis Hash聚合桶里,聚合桶结构如下:
1
2
3key: 作品id + 指标(点赞 or 收藏) + 时间窗口
field: 点赞、收藏
value: 这段时间窗口累积的点赞数、这段时间窗口累积的收藏数这样就实现了:大量更新操作不会直接达到最终的计数存储SDS处,而是在中间的Hash聚合桶累计一段时间,再批量直接写入最终存储,将多次写入变为一次写入;同时,时间窗口的划分,也能够保证对一个作品的大量点赞操作不会打到同一个聚合桶的key上
最后,再设计一个定时任务,每隔1s去读取聚合桶里累积的点赞数/收藏数,批量写入最终计数,写入成功后再删除已刷写的聚合字段,防止重复计算
4.3 什么是分片位图?为什么需要分片?
当前用户量少的情况下,一个作品的所有点赞用户通过一个位图bitmap来记录是可以的;但是随着用户量的增加,如果还用一个位图bitmap来记录,那么这个key就会非常大,对这个key的操作也会变得非常重,所以需要将一个作品的key分成多个,本项目中设计每个分片位数为32K位(即可以记录32K = 32768个用户的点赞数据),即每个分片4KB;通过usedId / 32768得到该用户的点赞数据在哪个分片,再通过userId % 32768得到该用户的点赞数据在该分片的哪一位。
分片的好处:
- 避免bigkey
- 统计总点赞数时,可以对多个分片并行执行
BITCOUNT再汇总 - 某些分片冷了,可以整体迁移到冷实例/冷存储
- 用户量级上去,只需要增加分片数或调整映射规则,无需推倒重来
4.4 点赞系统是如何实现重建的?
对需要重建点赞/收藏数的内容,列出该内容的所有分片位图键,对每个位图bitmap执行BITCOUNT统计1的数量,求和即为真实点赞/收藏数量,再写回对应的最终计数存储。(注意:重建过程需要加锁,重建结束删除对应的过时聚合字段)
4.5 点赞系统是如何保障幂等性的?
位图层面、事件生产的幂等
使用Lua脚本,只有位图对应位发生改变时,才会产生事件;否则不产生任何事件,也就不会多算点赞/收藏数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28/**
* 位图状态切换:仅在状态变化时返回成功,并产出增量事件。
* @param etype 实体类型
* @param eid 实体 ID
* @param uid 用户 ID
* @param metric 指标名称(like/fav)
* @param idx 指标索引(用于 SDS 固定结构定位)
* @param add 是否置位(true=添加,false=移除)
*/
private boolean toggle(String etype, String eid, long uid, String metric, int idx, boolean add) {
// 固定分片定位:按用户ID映射到 chunk 与分片内 bit 偏移,避免单键膨胀与热点
long chunk = BitmapShard.chunkOf(uid);
// 分片内位偏移
long bit = BitmapShard.bitOf(uid);
String bmKey = CounterKeys.bitmapKey(metric, etype, eid, chunk);
List<String> keys = List.of(bmKey);
List<String> args = List.of(String.valueOf(bit), add ? "add" : "remove");
Long changed = redis.execute(toggleScript, keys, args.toArray());
boolean ok = changed == 1L;
if (ok) {
int delta = add ? 1 : -1;
// 产出计数事件(异步聚合),分区按实体维度保证同实体事件顺序
eventProducer.publish(CounterEvent.of(etype, eid, metric, idx, uid, delta));
// 本地事件:触发缓存失效/旁路更新等快速路径
eventPublisher.publishEvent(CounterEvent.of(etype, eid, metric, idx, uid, delta));
}
return ok;
}聚合刷写的幂等
1
2
3
4
5
6
7redis.execute(incrScript, List.of(cntKey),
String.valueOf(CounterSchema.SCHEMA_LEN),
String.valueOf(CounterSchema.FIELD_SIZE),
String.valueOf(idx),
String.valueOf(delta));
// 成功后删除该字段,避免重复加算
redis.opsForHash().delete(aggKey, field);事件先写入聚合桶(Hash)
定时任务(每1秒)将增量折叠到SDS
刷写成功后立即删除聚合字段
即使定时任务多次执行,每个增量只会被刷写一次
重建场景的幂等
- 使用Redisson分布式锁保证只有一个线程重建,这个过程中其他获取锁失败的线程降级返回0(启用Redisson的看门狗机制去自动给锁续期,防止
BITCOUNT统计没统计完就释放锁,因为这个执行多个分片的BITCOUNT可能是很耗时的操作) - 重建完成后删除对应的聚合字段,避免 位图重建值 + 聚合增量 被重复计算
- 使用Redisson分布式锁保证只有一个线程重建,这个过程中其他获取锁失败的线程降级返回0(启用Redisson的看门狗机制去自动给锁续期,防止
4.6 使用位图判断点赞与否不会存在内存浪费的问题吗?
用户量很小时不会产生稀疏问题,后续可更换为稀疏位图,比如 roaring bitmap
4.7 一次点赞会访问三次Redis(bitmap+hash+sds),这是不是冗余的?为什么不直接存储在sds里?
并不冗余。
- 第一次访问Redis的bitmap,用于记录该用户是否点赞了该作品,用于实时展示“已点赞”的状态;然后生成一个kafka消息,用于后续点赞数更新
- 第二次访问Redis的hash,用于记录当前时间窗口内,该作品点赞数的增量(防止某个作品的总点赞数sds被不停访问更新,特别是对于热门作品,导致redis负载不均衡)
- 第三次访问Redis的sds,用于将hash中的增量点赞数刷写到总点赞数中去
4.8 对于点赞业务,如果消息还没被消费,那么如果在前端页面上刷新一下页面,这个点赞会消失吗?
不会消失,因为当用户点赞之后,触发作品对应的bitmap更新,将该用户对应的bitmap位设置为1,表示用户“已点赞”,之后才发出消息去更新点赞数,所以即使刷新页面,用户已点赞的状态不会消失
但是如果此时消息还没被消费,那么点赞数的更新可能会有延迟,但这是在能够接受的范围内的
五、Feed信息流
采用三级缓存架构且设计了缓存一致性策略,本地 Caffeine + Redis 页面缓存 + Redis 片段缓存。自定义 hotkey 探测机制,基于热点检测按层级延长缓存时长,叠加随机抖动抗雪崩。并设置单飞锁(single-flight)避免同一页并发回源风暴
5.1 介绍一下项目中用到的三级缓存
三级缓存用来存放一个页面里的所有推文数据:
- L2 本地Caffeine缓存:存放完整页面数据,命中成本最低,适合最热的公共页
- L1 Redis页面缓存:存放页面“骨架”,即当前页面文章的id列表,命中后用它来快速拼装页面
- L0 Redis片段缓存:存放每篇文章的小碎片(作者、封面、标题、计数等),用来按id拼装完整条目
获取页面数据的流程是:
- 优先读 L2:本地命中则直接返回完整页面,延迟最小。
- L2 未命中则读 L1:拿到页面骨架(ID 列表),随后按 ID 批量读取 L0 的条目碎片与计数碎片;缺片则进行最小化补全。
- L1 未命中则回源数据库:用单次查询拉取页面数据,同时并行批量获取计数;把结果写回 L0/L1,并把完整响应写入 L2,最后返回给用户。
5.2 为什么Redis要分成页面缓存和碎片缓存?不能像Caffeine一样存储完整页面数据吗?
如果Redis存储完整页面数据,虽然一次读取就能够返回所有数据,但是一个key包含整个页面的所有数据,容易产生bigkey问题;此外,页面内任何一篇文章更新(点赞数更新、内容更新),都会导致整个页面的缓存失效;而且,倘若当前页面和其他页面有同一篇文章,这篇文章的内容也没法复用。
相比之下,将Redis缓存分成页面缓存、片段缓存,当文章内容发生更新时,只需要使文章对应的那份片段缓存失效即可,无需将整页缓存失效,在最小范围内进行改动;若多个页面都包含同一篇文章,那么它们都能够复用同一篇文章的片段缓存,提高了空间利用率。
5.3 如何保证Caffeine、Redis、MySQL的一致性?
这个系统采用了混合策略,针对不同的更新场景使用不同的一致性保障机制:
| 更新类型 | 一致性策略 | 触发场景 |
|---|---|---|
| 结构性变更 | Cache-Aside + Double Delete | 发布、编辑、删除知文 |
| 计数变化 | 增量更新(Event-Driven) | 点赞、收藏(计数数据) |
策略1:Cache-Aside + Double Delete
适用场景:知文的元数据更新(标题、可见性、置顶、发布等)
为什么需要双删?
1 | |
延迟双删,要延迟多久?
延迟时间 = 读业务逻辑数据的耗时 + 几百毫秒。它为了确保读请求结束,写请求可以删除读请求可能带来的缓存脏数据。
策略2:增量更新
适用场景:高频变化的计数数据(知文的点赞数、收藏数)。
对于点赞这种高频的操作,如果也用双删,那么每次点赞都会删除所有缓存,每次都要回源DB,导致缓存命中率暴跌
执行流程:
1 | |
5.4 项目中的hotkey探测是怎么设计的?
本项目中的hotkey探测以滑动窗口为核心,为每个 Redis key 维护一个整型计数数组,数组的每个元素对应滑动窗口内的一个 “时间切片”,用于存储该时间段内的页面访问次数。
滑动窗口核心参数
- 滑动窗口总时长
window-seconds:统计热度的时间范围(如 60 秒,即仅统计最近 60 秒的访问量); - 分段粒度
segment-seconds:每个时间切片的时长(如 10 秒,即把 60 秒窗口划分为 6 个连续切片); - 分段数量
segments:滑动窗口包含的时间切片总数,由公式segments = window-seconds / segment-seconds计算得出(示例中 60s/10s=6,即数组长度为 6)。
| 参数名称 | 含义 | 默认值 | 调参建议 |
|---|---|---|---|
| window-seconds | 滑动窗口总时长 | 60 秒 | 流量波动大的场景可缩短至 30 秒(快速响应热点变化);流量稳定的场景可延长至 120 秒(更准确统计热度) |
| segment-seconds | 分段粒度(轮转频率) | 10 秒 | 确保 segments 在 6-12 之间:若 window-seconds=60 秒,segment-seconds 可在 5-10 秒之间调整;若 window-seconds=120 秒,segment-seconds 可在 10-20 秒之间调整 |
热度统计与轮转机制
- 全局指针管理:通过一个原子类型
AtomInteger的变量current,记录当前处于哪个时间窗口 - 窗口轮转机制:启用一个定时任务,每隔10s(分段粒度决定)去执行
current++,超出segments则归零,并将该索引对应的数组元素清空(该机制天然实现了热度自动降级) - 热度计算:对数组求和,结果即为当前时间窗口内,该 Redis key 的热度
- 计数逻辑:每访问一个key,找到该key对应的数组
arr,执行arr[current]++
热度分级与TTL动态扩展
根据每个 Redis key 的热度,划分为三个等级:
| 参数名称 | 含义 | 默认值 | 调参建议 |
|---|---|---|---|
| level-low | 低 / 中热度分界阈值 | 50 | 参考日常 QPS:若平均单页 QPS 为 10,可设为 30;若平均单页 QPS 为 50,可设为 100 |
| level-medium | 中 / 高热分界阈值 | 200 | 高热阈值建议为低热阈值的 3-5 倍,避免等级分布过于集中 |
| level-high | 高热上限阈值(可选) | 500 | 用于告警(如高热页面占比超 30% 需关注),不影响分级逻辑 |
每次访问某个key时,都需要reset该key的TTL,如果该key的热度较高,则需在baseTTL的基础上,再加上对应的扩展TTL,同时再加上随机抖动时间防止缓存雪崩。
| 参数名称 | 含义 | 默认值 | 调参建议 |
|---|---|---|---|
| extend-medium-seconds | 中热度扩展 TTL | 60 秒 | 初始可设为基础 TTL 的 1-2 倍,观察命中率变化;若命中率提升不明显,可适当增大 |
| extend-high-seconds | 高热扩展 TTL | 120 秒 | 不超过 window-seconds 的 2 倍,避免缓存过度停留导致数据陈旧 |
| jitter-percent | 随机抖动比例 | ±5% | 流量峰值高的场景可增大至 ±10%,进一步分散失效时间 |
5.5 项目中的single-flight有什么作用?
当本地缓存Caffeine、Redis缓存都失效时,需要到MySQL数据库查询,如果大量请求直接打到MySQL性能会非常差,这就是所谓的缓存击穿。single-flight主要思想就是只允许一个线程获取锁,到MySQL中去取数据并回源到Caffeine和Redis,这个过程中的其他线程都需要等待;直到完成了回源重建工作,其他线程才能获取锁,这时候缓存中已有数据,无需查询MySQL就可返回。
5.6 项目有对缓存雪崩、缓存击穿、缓存穿透做预防和处理吗?
- 缓存穿透:缓存空值,对“不存在内容”的查询直接写入一个短 TTL 的 NULL 值,下次请求命中后不再打数据库
- 缓存雪崩:设置缓存过期时间时,加上一个随机抖动值,防止大量key同时过期;同时还采用自定义的hotkey探测,动态延长热点key的TTL
- 缓存击穿:采用single-flight锁,热点key过期时只允许一个线程操作数据库查询数据并执行重建工作
5.7 为什么选用Caffeine?Caffeine解决了guava的哪些痛点?
核心算法:从 LRU 到 W-TinyLFU
- Guava 的痛点(LRU): Guava 使用的是经典的 LRU (Least Recently Used) 算法。LRU 在应对突发流量(稀疏流量)时表现很差。例如,如果有一波冷数据瞬间被大量访问,LRU 会把真正的热数据挤出缓存,导致缓存命中率骤降。
- Caffeine 的解决(W-TinyLFU): Caffeine 使用了 W-TinyLFU 算法。它结合了 LFU(频率)和 LRU(新鲜度)的优点:
- 它用极小的内存空间(类似布隆过滤器的 Count-Min Sketch)记录数据的访问频率。
- 当新数据进来时,它会对比新数据和待淘汰数据的“频率”,如果新数据访问频率更高才准入。
- W-TinyLFU算法原理
并发性能:由“段”到“条”
- Guava 的痛点(Segment): Guava 的设计思路类似于
ConcurrentHashMap(Java 7 之前),通过分段锁 (Segment) 来减少竞争。但在高并发下,对同一个段的访问依然会有锁竞争。此外,Guava 在读取数据时也会执行一些清理维护操作,这进一步加剧了竞争。 - Caffeine 的解决(无锁化/异步): Caffeine 借鉴了数据库写前日志(WAL)的思想。
- 读取操作: 几乎是无锁的,它将读取记录放入一个环形缓冲区(Ring Buffer)中。
- 维护操作: 将缓存的清理、写入、统计等繁重任务交给独立的线程池(ForkJoinPool)异步执行。
六、AI问答系统
开发 RAG 知识问答系统,实现用户调用接口→索引检查→向量检索→Prompt 构造→大模型流式生成的全流程,通过合理分块、幂等删除保持单一版本、预索引减少首次提问等待时间等,显著提升用户围绕单篇知文的智能问答效率与准确性。
6.1 向量检索用的是哪个数据库?为什么选择它?索引维度是多少?召回率是多少?
Elasticsearch
Elasticsearch 是成熟的分布式搜索引擎,支持向量检索的同时也支持传统的全文检索
Spring AI 原生支持:Spring AI 框架提供了开箱即用的 Elasticsearch Vector Store 集成
索引维度是1536 维,embedding使用的是阿里云 DashScope 的 text-embedding-v4 模型;回答采用deepseek模型
采用了宽召回策略来提高召回率:
采用
fetchK = max(topK × 3, 20)的宽召回策略,即召回 3 倍目标数量的候选,再进行后过滤通过 metadata.postId 进行服务端过滤,避免跨帖子污染
6.2 “合理分块”的策略是什么? 块大小如何确定?块之间有重叠吗?如何处理跨块的语义信息?
先按 Markdown 标题(以 # 开头的行)进行段落划分,保持逻辑结构的完整性;再对每个段落进行进一步切分,每个chunk <= 800字符,避免单个 chunk 过长,同时块之间保留100个字符的重叠,确保跨块的关键信息不会被切断。
6.3 “幂等删除保持单一版本”具体怎么实现?如果用户编辑了知文,旧版本的向量如何清理?如何避免检索到过期内容?
项目采用指纹检测 + 先删后写的策略来保持单一版本:
- 先检测文章的指纹,如果未发生变化则跳过重建
- 否则先删除所有旧版本向量
- 再重新写入新版本向量,并携带新的指纹信息
6.4 “预索引”是在什么时候实现的?
- 发布文章成功后触发一次预索引
- 回答时检查文章是否发生变化,若发生变化则生成新索引
6.5 检索的原理是什么?
1 | |
基于向量距离的 kNN/ANN 搜索
- Embedding(向量化): 系统首先会调用 Embedding Model,将输入的自然语言
query转换成一个1536维向量。 - Distance Calculation(距离计算): 拿着这个查询向量,到
vectorStore(向量数据库)中去计算它与库中存储的 Document 向量之间的距离(通常使用余弦相似度 Cosine 或 欧氏距离 L2)。 - Ranking(排序): 找出距离最近(相似度最高)的
fetchK个文档返回。