Kafka工作原理
Kafka工作原理

1. Kafka核心概念
Message(消息):Kafka中的数据单元称为消息。可以将消息看成是数据库中的一条“数据行”或一条“记录”。消息是Kafka中最基本的单位,每一条消息都是一个独立的记录,包含消息的键、值、时间戳等信息。
Batch(批次):为了提高效率,Kafka将消息进行批量处理。消息被分批写入Kafka,这种方式提高了吞吐量,但也会增加响应时间。批次处理使得Kafka能够以更高效的方式进行I/O操作,从而提升整体性能。
Producer(生产者):Producer即生产者,消息的产生者,是消息的入口。
Broker:Broker是kafka实例,每个服务器上有一个或多个kafka的实例,我们姑且认为每个broker对应一台服务器。每个kafka集群内的broker都有一个不重复的编号,如图中的broker-0、broker-1等……
主题(Topic):主题是Kafka中用于消息分类的概念,类似于数据库中的表。每个主题都可以包含多个消息,生产者将消息发送到主题,消费者从主题中读取消息。通过主题,我们可以将不同类型的消息分开管理。在每个Broker都可以创建多个Topic。(Topic是逻辑上的消息分类)
分区(Partition):为了方便扩展和管理,Kafka中的每个Topic可以分为多个Partition。分区使得Kafka能够横向扩展,将消息分布在多个节点上。单个分区内的消息是有序的,但在多个分区间无法保证全局有序。如果希望消息全局有序,可以将分区数设置为一。(Partition是物理上的消息分类)
每个topic可以有多个partition,partition的作用是做负载,提高kafka的吞吐量。同一个topic在不同的分区的数据是不重复的,partition的表现形式就是一个一个的文件夹(里面存储Segment)!
副本(Replication):每一个分区都有多个副本,副本的作用是做备胎。当主分区(Leader)故障的时候会选择一个备胎(Follower)上位,成为Leader。在kafka中默认副本的最大数量是10个,且副本的数量不能大于Broker的数量,follower和leader绝对是在不同的机器,同一机器对同一个分区也只可能存放一个副本(包括自己)。副本机制是Kafka高可靠性的基础。
AR:分区中所有副本称为 ARISR:所有与主副本保持一定程度同步的副本(包括主副本)称为 ISROSR:与主副本滞后过多的副本组成 OSR
消费者(Consumer):消费者,即消息的消费方,是消息的出口。
消费者组(Consumer Group):我们可以将多个消费者组成一个消费者组,在kafka的设计中同一个分区的数据只能被消费者组中的某一个消费者消费。同一个消费者组的消费者可以消费同一个topic的不同分区的数据,这也是为了提高kafka的吞吐量!(一个消费者去处理一个Topic下的多个Partition效率 肯定不如 一个消费者组里的多个消费者一起去消费一个Topic下的不同Partition吧! ————> 消费者组也引出了rebalance的问题 )
2. Kafka的优点
- 高性能、高吞吐量、低延迟:Kafka 生产和消费消息的速度都达到每秒10万级
- 高可用:所有消息持久化存储到磁盘,并支持数据备份防止数据丢失
- 高并发:支持数千个客户端同时读写
- 容错性:允许集群中节点失败(若副本数量为n,则允许 n-1 个节点失败)
- 高扩展性:Kafka 集群支持热伸缩,无须停机
3. Kafka如何避免消息丢失?
引用:JavaGuide
3.1 生产者丢失消息的情况
生产者(Producer) 调用send方法发送消息之后,消息可能因为网络问题并没有发送过去。
所以,我们不能默认在调用send方法发送消息之后消息发送成功了。为了确定消息是发送成功,我们要判断消息发送的结果。但是要注意的是 Kafka 生产者(Producer) 使用 send 方法发送消息实际上是异步的操作,我们可以通过 get()方法获取调用结果,但是这样也让它变为了同步操作.
但是一般不推荐这么做!可以采用为其添加回调函数的形式
如果消息发送失败的话,我们检查失败的原因之后重新发送即可!
3.2 消费者丢失消息的情况
我们知道消息在被追加到 Partition(分区)的时候都会分配一个特定的偏移量(offset)。偏移量(offset)表示 Consumer 当前消费到的 Partition(分区)的所在的位置。Kafka 通过偏移量(offset)可以保证消息在分区内的顺序性。
当消费者拉取到了分区的某个消息之后,消费者会自动提交了 offset。自动提交的话会有一个问题,试想一下,当消费者刚拿到这个消息准备进行真正消费的时候,突然挂掉了,消息实际上并没有被消费,但是 offset 却被自动提交了。
解决办法也比较粗暴,我们手动关闭自动提交 offset,每次在真正消费完消息之后再自己手动提交 offset 。 但是,细心的朋友一定会发现,这样会带来消息被重新消费的问题。比如你刚刚消费完消息之后,还没提交 offset,结果自己挂掉了,那么这个消息理论上就会被消费两次。
3.3 Kafka弄丢了消息
我们知道 Kafka 为分区(Partition)引入了多副本(Replica)机制。分区(Partition)中的多个副本之间会有一个叫做 leader 的家伙,其他副本称为 follower。我们发送的消息会被发送到 leader 副本,然后 follower 副本才能从 leader 副本中拉取消息进行同步。生产者和消费者只与 leader 副本交互。你可以理解为其他副本只是 leader 副本的拷贝,它们的存在只是为了保证消息存储的安全性。
试想一种情况:假如 leader 副本所在的 broker 突然挂掉,那么就要从 follower 副本重新选出一个 leader ,但是 leader 的数据还有一些没有被 follower 副本的同步的话,就会造成消息丢失。
设置 acks = all
解决办法就是我们设置 acks = all。acks 是 Kafka 生产者(Producer) 很重要的一个参数。
acks 的默认值即为 1,代表我们的消息被 leader 副本接收之后就算被成功发送。当我们配置 acks = all 表示只有所有 ISR 列表的副本全部收到消息时,生产者才会接收到来自服务器的响应. 这种模式是最高级别的,也是最安全的,可以确保不止一个 Broker 接收到了消息. 该模式的延迟会很高
Kafka的Producer有三种ack机制,参数值有0、1 和 -1
- 0: 相当于异步操作,Producer 不需要Leader给予回复,发送完就认为成功,继续发送下一条(批)Message。此机制具有最低延迟,但是持久性可靠性也最差,当服务器发生故障时,很可能发生数据丢失
- 1: Kafka 默认的设置。表示 Producer 要 Leader 确认已成功接收数据才发送下一条(批)Message。不过 Leader 宕机,Follower 尚未复制的情况下,数据就会丢失。此机制提供了较好的持久性和较低的延迟性
- -1: Leader 接收到消息之后,还必须要求ISR列表里跟Leader保持同步的那些Follower都确认消息已同步,Producer 才发送下一条(批)Message。此机制持久性可靠性最好,但延时性最差
设置 replication.factor >= 3
为了保证 leader 副本能有 follower 副本能同步消息,我们一般会为 topic 设置 replication.factor >= 3。这样就可以保证每个 分区(partition) 至少有 3 个副本。虽然造成了数据冗余,但是带来了数据的安全性。
设置 min.insync.replicas > 1
一般情况下我们还需要设置 min.insync.replicas> 1 ,这样配置代表消息至少要被写入到 2 个副本才算是被成功发送。min.insync.replicas 的默认值为 1 ,在实际生产中应尽量避免默认值 1。
但是,为了保证整个 Kafka 服务的高可用性,你需要确保 replication.factor > min.insync.replicas 。为什么呢?设想一下假如两者相等的话,只要是有一个副本挂掉,整个分区就无法正常工作了。这明显违反高可用性!一般推荐设置成 replication.factor = min.insync.replicas + 1。
设置 unclean.leader.election.enable = false
多个 follower 副本之间的消息同步情况不一样,当我们配置了unclean.leader.election.enable = false 时,当 leader 副本发生故障时就不会从 follower 副本中和 leader 同步程度达不到要求的副本中选择出 leader ,这样降低了消息丢失的可能性。
4. Kafka如何保证消息的消费顺序

每次添加消息到 Partition(分区) 的时候都会采用尾加法,如上图所示。 Kafka 只能为我们保证 Partition(分区) 中的消息有序。
方法一:既然消费顺序不一致是由于一个Topic有多个Partition,而Kafka只能保证一个Partition内有序,那么令一个Topic只对应一个Partition就可以保证消息消费顺序。
方法二:发送消息时指定Partition,消息就会被发送到对应的Partition;发送消息时指定Key,同一个Key的消息会被发送到同一个Partition。
选择的Partition = hashcode(key) % Partition总数
5. Kafka如何保证消息不被重复消费
kafka 出现消息重复消费的原因:
生产阶段由于网络波动导致同一条消息被重复发送
服务端侧已经消费的数据没有成功提交 offset(根本原因)。
Kafka 侧 由于服务端处理业务时间长或者网络链接等等原因让 Kafka 认为服务假死,触发了分区 rebalance。
为了维持Consumer与Consumer Group之间的关系,Consumer 会周期性地发送 hearbeat 到 Group Coodinator,如果有 hearbeat 超时或未收到 hearbeat,coordinator 会认为该Consumer已经退出,那么它所订阅的Partition会分配到同一组内的其他Consumer上,这个过程称为 rebalance。rebalance期间所有消费者暂停消费,提交当前消费状态,等待coordinator重新分配分区
解决方案:
- Kafka幂等性生产:通过
Producer ID + 消息序列号Seq Number来唯一标识一条消息,避免重复发送 - 消费消息服务做幂等校验,比如 Redis 的 set(消息的uuid存入Redis set中,消费前先检查是否存在)、MySQL 的主键等天然的幂等功能。这种方法最有效。
- 将
enable.auto.commit参数设置为 false,关闭自动提交,开发者在代码中手动提交 offset。那么这里会有个问题:什么时候提交 offset 合适?- 处理完消息再提交:依旧有消息重复消费的风险,和自动提交一样
- 拉取到消息即提交:会有消息丢失的风险。允许消息延时的场景,一般会采用这种方式。然后,通过定时任务在业务不繁忙(比如凌晨)的时候做数据兜底。
6. Kafka重试机制
6.1 消费失败会怎么样?
在消费过程中,当其中一个消息消费异常时,会不会卡住后续队列消息的消费?这样业务岂不是卡住了?
在默认配置下,当消费异常会进行重试,重试多次后会跳过当前消息,继续进行后续消息的消费,不会一直卡在当前消息。
6.2 默认重试多少次?
Kafka 消费者在默认配置下会进行最多 10 次 的重试,每次重试的时间间隔为 0,即立即进行重试。如果在 10 次重试后仍然无法成功消费消息,则不再进行重试,消息将被视为消费失败。
6.3 重试失败后的消息如何再次处理?
死信队列(Dead Letter Queue,简称 DLQ) 是消息中间件中的一种特殊队列。它主要用于处理无法被消费者正确处理的消息,通常是因为消息格式错误、处理失败、消费超时等情况导致的消息被”丢弃”或”死亡”的情况。
当消息进入队列后,消费者会尝试处理它。如果处理失败,或者超过一定的重试次数仍无法被成功处理,消息可以发送到死信队列中,而不是被永久性地丢弃。在死信队列中,可以进一步分析、处理这些无法正常消费的消息,以便定位问题、修复错误,并采取适当的措施。
7. Kafka高性能原因
7.1 使用批量消息提升服务端处理能力
- 发送端:当我们调用send()方法发送一条消息后,无论我们是同步发送还是异步发送,Kafka并不会立刻把这条消息发送出去,它会先把这条消息存放在内存中,然后选择合适的时机把缓存的所有消息组成一批,一次性的发给Broker。减少了网络调用次数。
- Broker:整个处理流程中,无论是写入磁盘、从磁盘读出来、还是复制到其他副本,批消息都不会被解开,一直是作为一条“批消息”进行处理的。减少了磁盘IO次数。
- 消费端:消息同样是以批为单位进行传递的,Consumer从Broker拉到一批消息后,在客户端把批消息解开,再一条一条交给用户代码处理。减少了网络调用次数。
构建批消息和解开批消息分别在发送端和消费端的客户端完成,不仅减轻了Broker的压力,还减少了Broker处理请求的次数,提升了总体的处理能力
7.2 顺序读写提升磁盘IO性能
每个分区,它把从Producer收到的消息,顺序地写入对应的log文件中,一个文件写完了,就开启一个新的文件继续顺序写下去。消费的时候,也是从某个全局的位置开始,顺序地把消息读出来
7.3 利用PageCache加速消息读写
当生产者发送消息时,这些数据并不是立即落盘,而是被写入操作系统提供的页缓存中。这是一块用于缓存磁盘数据的内存区域,可以延迟刷盘,从而显著提升写入性能。
在消费过程中,如果消费者在写入后短时间内就开始拉取数据,那么这些数据往往还停留在页缓存中,不需要再从磁盘读取,这就极大减少了磁盘IO。Kafka的“写后即读”特性与PageCache的缓存策略高度契合,形成了一种天然的局部性优化。
7.4 使用零拷贝技术加速消费流程
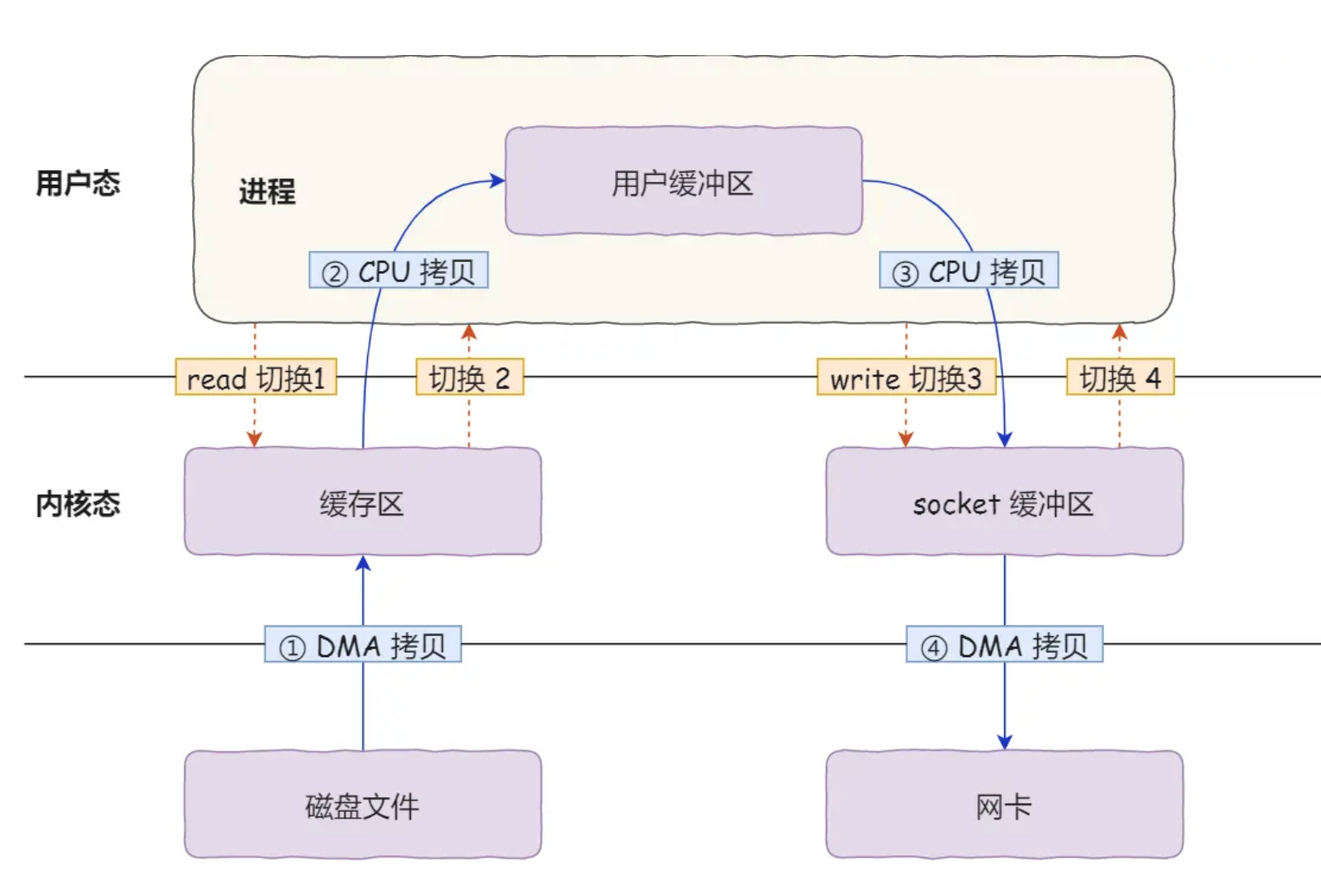
2次系统调用
一次是read(),一次是write(),每次系统调用都得先从用户态切换到内核态,等内核完成任务后,再从内核态切换回用户态,所以共发生了4次用户态与内核态的上下文切换。
上下文切换到成本并不小,一次切换需要耗时几十纳秒到几微秒,虽然时间看上去很短,但是在高并发的场景下,这类时间容易被累积和放大,从而影响系统的性能。
4次数据拷贝
还发生了4次数据拷贝,其中两次是DMA的拷贝,另外两次则是通过CPU拷贝的,下面说一下这个过程:
- 第一次拷贝:把磁盘上的数据拷到操作系统内核的缓冲区里,很多资料里也将其叫作Read Buffer,这个拷贝的过程是通过DMA搬运的。
- 第二次拷贝:把内核缓冲区的数据拷贝到用户的缓冲区里,于是我们应用程序就可以使用这部分数据了,这个拷贝到过程是由CPU完成的。
- 第三次拷贝:把刚才拷贝到用户的缓冲区里的数据,再拷到内核的socket的缓冲区里,这个过程依然还是由CPU搬运的。
- 第四次拷贝:把内核的socket缓冲区里的数据,拷到网卡的缓冲区里,这个过程又是由DMA这个控制器搬运的。
我们回过头看这个数据传输的过程,我们只是搬运一份数据,结果却搬运了4次,过多的数据拷贝无疑会消耗CPU资源,大大降低了系统性能。
优化思路
减少系统调用 和 数据拷贝次数
- 减少系统调用:一次系统调用会发生2次上下文切换,从用户态切换到内核态,内核执行完成后再从内核态切换回用户态
- 减少数据拷贝:上面的第二、三次拷贝是不必要的,因为在数据传输过程中,我们不会在用户态中对数据进行加工,也就没必要把数据搬运到用户态
零拷贝技术
所谓的零拷贝是指将数据在内核空间直接从磁盘文件复制到网卡中,而不需要经由用户态的应用程序之手。这样既可以提高数据读取的性能,也能减少核心态和用户态之间的上下文切换,提高数据传输效率。
这种方式的优势非常明显。系统调用次数从两次降为一次,内核态和用户态的切换从四次降到两次,数据拷过程也由四次减少到两次。同时,配合DMA(直接内存访问)机制,还可以进一步减轻CPU的负担。
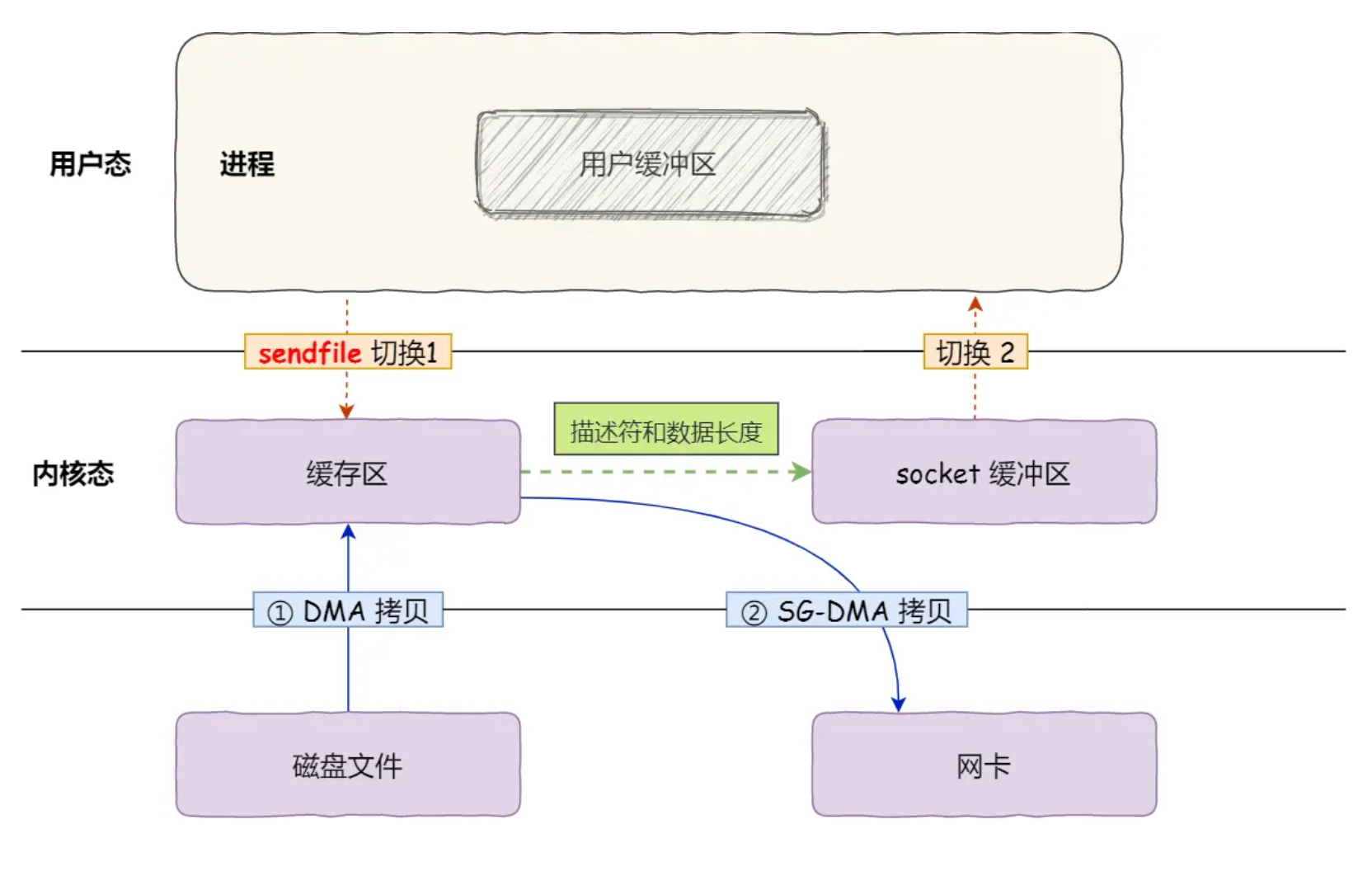
具体流程如下:
sendfile开启流程,可以看到sendfile是代替了read和write,相当于只有一次系统调用了- 操作系统将数据从磁盘通过DMA加载到内核空间的缓存区
- 操作系统将数据的描述符拷贝到Socket缓冲区中。Socket缓冲区仅仅会拷贝一个描述符过去,不会拷贝数据。
- 操作系统直接将数据从内核空间的缓存区传输到网卡中,并通过网卡将数据发送给接收方,这也是通过DMA来做的,不过这里的DMA叫SG-DMA,基本上现阶段的网卡都是支持SG-DMA的,所以没有什么特别的,知道它是一种加强的DMA技术就行了,甚至面试时候就说是DMA也是一样的。
7.5 消息压缩
Kafka支持在生产端或Broker端对消息进行压缩,以减少网络传输的数据体积。数据压缩适合带宽资源紧张而CPU资源相对宽裕的场景,能有效提升整体传输效率,是Kafka保持高吞吐的重要机制之一。
8. Kafka的分层设计机制与索引设计
8.1 分层设计机制
Kafka采用 Topic - Partition - Segment 的分层设计机制:
Topic作为业务逻辑隔离的基本单位,实现数据独立性;
每个Topic进一步拆分为多个Partition,通过并行写入与消费实现横向扩展以提升吞吐能力;
每个Partition由多个按大小(默认1GB,可配置log.segment.size)滚动生成的Segment组成,每个Segment包含:
- .log数据文件(每个段的文件名以该段的起始偏移量命名,例如
00000000000000000000.log) - 用于快速定位的.index(偏移量索引)
- .timeindex(时间索引)文件
索引文件加载至内存以优化查询效率,通过该分层结构实现高并发、高吞吐场景下的数据高效管理与扩展。
- .log数据文件(每个段的文件名以该段的起始偏移量命名,例如
8.2 索引机制
根据offset定位消息的具体步骤
步骤一:确定消息所在的日志分段
当你指定一个偏移量offset时,Kafka首先会根据offset的大小确定消息所在的日志分段segment。由于segment是按照偏移量顺序排列的,Kafka可以通过比较offset和每个segment的起始偏移量,快速找到包含该offset的日志分段.
步骤二:使用索引文件加速查找
在确定了消息所在的日志分段后,Kafka会使用对应的索引文件来加速消息的查找过程。
- 偏移量索引文件(.index):该文件记录了部分消息的偏移量和它们在.log文件中的物理位置。Kafka会在这个索引文件中进行二分查找,找到小于或等于指定偏移量的最大偏移量记录,从而得到一个近似的物理文件位置。
- 时间戳索引文件(.timeindex):如果需要根据时间戳来定位消息,Kafka会先在时间戳索引文件中查找指定时间戳对应的偏移量,然后再使用偏移量索引文件进一步定位消息。
步骤三:在日志文件中查找消息
通过索引文件得到近似的物理文件位置后,Kafka会从该位置开始在.log文件中顺序查找,直到找到指定偏移量的消息。由于已经通过索引文件缩小了查找范围,这个顺序查找的过程通常非常快。